ECCV 2024
Arxiv
Github
Ronglai Zuo, Fangyun Wei, Zenggui Chen, Brian Mak, Jiaolong Yang, Xin Tong
Introduction
청각 장애인에게 수어(sign language)는 주요한 의사소통 수단이다. 기존 연구들은 주로 수어를 구어(spoken language)로 번역하는 수어 번역(Sign2Spoken)에 집중해 왔다. 그러나 본 논문은 방향을 전환하여, 구어에서 수어를 생성(Spoken2Sign)하는 데 초점을 맞춘다.

이전 수어 생성(sign language production) 연구들은 대부분 그림 (a)와 같이 키포인트(keypoint)를 통해 결과를 표현하는 방식에 집중해 왔다. 그러나 키포인트 표현은 수어 사용자들에게 해석상의 어려움을 유발한다. 일부 연구들은 그림 (b)와 같이 키포인트를 활용해 수어 비디오를 생성했으나, 이러한 2D 비디오 형식은 blurriness와 visual distortion에 취약하다.
이에 본 연구는 Spoken2Sign을 위해 그림 (c)와 같이 3D 아바타를 활용하여 번역 결과를 표현하는 방식을 제안한다. 기존 방식과 달리 본 연구는 이해 가능성 향상에 우선순위를 두며, 특히 수어 동작에 특화된 3D human pose prior을 통합하여 multi-view에서 번역 결과를 표현할 수 있도록 한다.

위 그림과 같이 본 연구의 Spoken2Sign baseline은 세 단계로 이뤄진다.
1) dictionary 구축
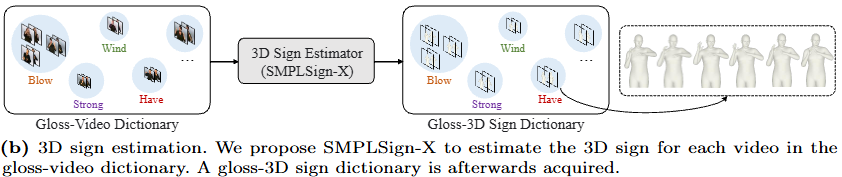
2) 3D sign estimation
3) retrieve-then-connect 패러다임
Dictionary Construction. 이 단계에서는 위 그림 (a)와 같이 M개의 gloss로 구성된 gloss-video 사전을 만든다. 기존 Sign language Recognition dataset은 일반적으로 Isolated SLR(ISLR), Continuous SLR(CSLR) 두 개로 구분된다. ISLR 데이터셋은 본질적으로 수어 사전 역할을 하지만, text-gloss 시퀀스 데이터가 부족하여 text-to-gloss sequence translation에 어려움이 존재한다. 대안으로, 저자들은 CSLR 데이터셋을 활용하는 방법을 제안한다. 구체적으로는 CTC(Connectionist Temporal Classification) loss로 학습된 CSLR 모델을 이용해 연속 수어 비디오를 개별 수어로 분할한다. 이렇게 생성된 고립 수어는 의미 없는 동작(E.g. 수어 시작·끝 부분의 손 올리기/내리기)을 배제하기 때문에, 이후 sign connection에 더 적합하다.
3D Sign Estimation. 이 단계에서는 앞서 구축한 gloss-video 사전을 3D sign으로 변환하는 것을 목표로 한다. 저자들은 최근 3D whole-body parametric model과 monocular 3D whole-body reconstruction 연구에 주목하여, 수어에 특화된 SMPLSign-X를 제안한다. 이는 SMPLify-X가 shape, pose, expression 파라미터를 최적화하는 방식에서 착안한 것으로, 저자들은 여기에 temporal consistency를 강화하고 수어 아바타에 특화된 3D pose prior를 적용하였다(Figure 2b).
Spoken2Sign Translation. 이 단계(Figure 2c)는 본 연구의 핵심 아이디어를 보여준다. 먼저 Text2Gloss 모델을 학습하여 gloss 시퀀스를 예측한 뒤, 각 gloss에 대해 gloss-3D sign 사전에서 대응되는 3D 수어를 검색한다. 그러나 인접한 두 수어는 매끄럽게 연결되지 않아 번역 결과가 부자연스러울 수 있다. 기존 연구들은 이를 무시하거나, 2D 키포인트 기반 length interpolation으로 처리해 왔다. 이에 본 연구는 각 co-articulation의 길이를 동적으로 예측할 수 있는 lightweight sign connecto를 설계하여, 인접한 수어들을 3D 공간에서 자연스럽게 연결하도록 했다.
Methodology
Dictionary Construction.
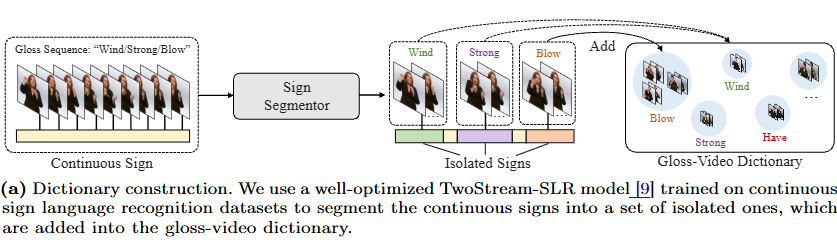
Spoken2Sign에서 기존 데이터셋은 gloss 단위의 비디오를 제공하지 않는다. 이에 저자들은 CSLR 모델이 CTCforced alignment 알고리즘을 통해 연속 수어 비디오를 일련의 수어 단위로 분할할 수 있다는 점에 주목하였다. 이를 활용하여 Figure 2와 같이 sign dictionary을 구축하였다. 그 결과, M개의 gloss를 포함하는 사전을 얻을 수 있으며, 동시에 co-articulation 집합도 생성된다. 이는 두 인접 수어 간의 전환을 의미하며, CTC loss에서의 blank class에 해당한다. 이렇게 얻은 co-articulation 데이터셋은 이후 sign connector 학습에 활용된다.
3D Sign Estimation.
Preliminaries of SMPLify-X and SMPL-X. SMPLify-X는 monocular image 하나로부터 인체의 body pose, hand pose, facial expression을 포함한 3D representation을 추정하는 널리 사용되는 방법이다. (방법론을 잘 모른다면 여기 참조) 이때 생성된 3D 표현은 SMPL-X 모델이라 하며 다음과 같은 학습 가능한 파라미터들로 정의된다:
* global orientation $\zeta \in \mathbb{R}^3$
* body shape $\beta \in \mathbb{R}^{10}$
* facial expression $\psi \in \mathbb{R}^{10}$
* body pose $\theta \in \mathbb{R}^{3N}$
(여기서 pose parameter는 kinematics map에 정의된 parent joint에 대한 상대 axis-angle rotation을 나타냄)
이러한 파라미터들을 이용해 SMPL-X 모델은 10,475개의 vertice와 118개의 3D joint $D \in \mathbb{R}^{118 \times 3}$를 포함하는 mesh를 생성한다.
monocular 이미지에 SMPL-X를 맞추기 위해 저자들은 먼저 HRNet을 사용하여 COCO-Wholebody 데이터셋에서 학습된 모델로부터 2D 키포인트 $K \in \mathbb{R}^{118 \times 2} $를 추정한다. 이때 COCO-Wholebody의 키포인트 일부만을 사용하여 SMPL-X 관절과 alignment를 수행한다. 이후 SMPLify-X는 다음 목적함수를 최소화하도록 $\zeta$,$\beta$, $\psi$, $\theta$ 최적화하도록 설계한다:
$$ \mathcal{L} = \mathcal{L}_{\text{joint}} + \mathcal{L}_{\text{prior}} + \mathcal{L}_{\text{penetration}} $$
- $ \mathcal{L}_{\text{joint}}$: 2D 키포인트 $K$와 투영된 키포인트 $P(D)$ 간의 거리 최소화
- $ \mathcal{L}_{\text{prior}}$: 손 포즈, 얼굴 포즈, 신체 형태 및 표정에 대한 prior 지식을 반영하여 극단적 신체 상태를 억제
- $ \mathcal{L}_{\text{penetration}}$: penetraion 과 self-collision을 방지하기 위한 regularization term
$$ \mathcal{L}{\text{joint}} = \frac{1}{|\mathcal{J}|} \sum{i \in \mathcal{J}} \gamma_i \omega_i \ell_r \big( P(D_i) - \mathcal{K}_i \big) $$
와 같이 정의된다.
SMPLSign-X. 저자들은 위의 SMPLify-X를 확장하여 입력을 수어 비디오로 확장하고 수어 특성을 반영해 추정 품질을 개선하였다. 이는 세 가지 관찰에 기반한다.
1) 수어 영상에는 등장하지 않는 관절은 최적화 대상이 존재하지 않는다.
2) 수어자의 상체는 수어 동작을 수행하는 동안 직립 상태를 유지한다.
3) 각 프레임을 독립적으로 SMPL-X에 맞추면 temporal inconsistency가 발생한다.
이를 해결하기 위해 저자들은 SMPLSign-X의 목적 함수를 다음과 같이 정의한다:
$$ \mathcal{L} = \mathcal{L}_{\text{joint}} + \mathcal{L}_{\text{prior}} + \mathcal{L}_{\text{penetration}} + \lambda_1 \mathcal{L}_{\text{unseen}} + \lambda_2 \mathcal{L}_{\text{upright}} + \lambda_3 \mathcal{L}_{\text{smooth}} $$
$ \mathcal{L}_{\text{unseen}}$: 보이지 않는 키포인트를 rest pose로 유도하는 regularization term으로, HRNet의 confidence가 $ \lambda$이하인 경우 해당 키포인트를 unseen으로 간주한다:
$$ \mathcal{L}_{\text{unseen}} = \sum_{i \in \mathcal{J}_{\text{unseen}}} \ell_r(\theta_i - \hat{\theta}_i) $$
$ \mathcal{L}_{\text{upright}}$: 상체 직립을 유지하기 위한 regularization term으로, 목과 골반의 키포인트 집합 내 깊이 값을 일관성 있게 보존한다.
$$ \mathcal{L}_{\text{upright}} = \sum_{i,j \in \mathcal{J}_{\text{upright}}} \ell_r(d_i - d_j) $$
$ \mathcal{L}_{\text{smooth}}$: 시간적 일관성을 유지하는 loss로 이전 프레임의 포즈 파라미터를 참조한다.
$$ \mathcal{L}_{\text{smooth}} = \sum_{i \in \mathcal{J}_\theta} \gamma_i \ell_r(\theta_i - \theta_i^{\text{pre}}) $$
Spoken2Sign Translation.

Text2Gloss Translator. 저자들은 Text2Gloss 번역을 수행하기 위해 mBART 모델을 활용하여 이를 학습하였다. 성능의 경우 수어에서 일반적으로 사용되는 데이터 셋 Phoenix-2014T / CSL-Daily에 대해 각각 BLEU-4 기준 29.27/31.88을 기록하였다.
Sign Retrieval. 예측된 글로스에 대응되는 3D 수어를 retrieve 한다. 하나의 글로스가 여러 개의 3D 수어와 연결될 수 있기 때문에 최적의 수어를 찾기 위한 전략이 필요하다. 이를 위해 저자들은 사전 내 모든 수어 예시를 기반으로 ISLR 모델을 학습하였다. 검색 시, 후보 수어들을 ISLR 모델에 입력하고, gloss query에 대해 가장 높은 confidence를 가지는 수어를 선택한다.

Sign Connector. 위 그림과 같이 저자들은 인접한 두 3D 수어가 연결될 때 발생하는 co-articulation의 지속시간을 예측한다. 이를 위해 저자들은 $ \left( \mathcal{D}_{\mathcal{J}{SC}}^{\text{pre}}, L, \mathcal{D}_{\mathcal{J}{SC}}^{\text{next}} \right) $ co-articulation 집합을 생성한다. 이는 순서대로 이전 수어 3D 관절, co-articulation 지속 시간, 이후 수어 3D 관절을 의미한다. sign connector는 4-layer MLP로 구현되며 , 입력은 $(D^{pre}_{J{SC}}, D^{next}_{J{SC}}, |D^{pre}_{J{SC}} - D^{next}_{J{SC}}|)$의 concatenation이다. 손실 함수는 예측된 값과 실제 $L$ 간의 차이를 줄이는 L1 loss를 사용한다.
학습된 sign connector를 통해 인접한 두 수어 $(S_{k-1}, S_k)$ 사이의 공동 발화 지속 시간 $\hat{L}_k$을 예측한다. 이후 $S_{k-1}$의 마지막 프레임과 $S_k$의 첫 프레임 사이에 $\hat{L}_k$개의 프레임을 interpolation하여 공동 발화 구간 $C^{k-1}_k$을 생성한다. 이를 통해 최종적으로 ${S_1, C_{2}^1, S_2, ..., S_{K-1}, C_{K}^{K-1}, S_K}$ 형태의 연속적인 3D 수어 시퀀스를 얻을 수 있다.
Rendering Module. 저자들은 Blender toolkit을 사용하여 생성한 3D 수어 시퀀스를 랜더링한다. 이때 SMPL-X 모델의 pose와 facial expression 파라미터가 아바타를 drive 하는 데 사용된다.
Experiments
Qualitative Evaluation. 생성된 3D 아바타를 통해 번역 결과를 시각화하였으며, 위 그림과 같이 GT와 비교했을 때 전반적으로 유사한 수준임을 확인하였다.

Qualitative Evaluation. 본 연구의 실험 결과 역번역 성능 기준 SOTA를 달성하였다.

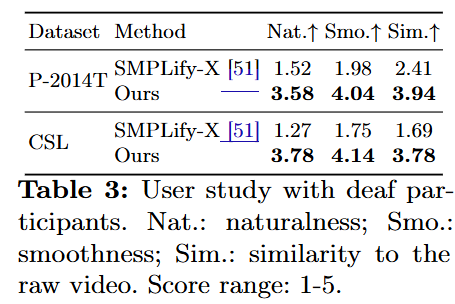
제안한 SMPLSign-X의 성능을 측정한 결과, 2D keypoint loss가 가장 낮고 temporal consistency가 가장 높게 나타났다. 이는 수어 특화 사전 지식을 통합한 접근법의 효과를 검증하는 결과이다. 또한 청각장애인에 대한 user study 결과 기존 모델 대비 우수한 성능을 보였다.

제안한 세 가지 Loss function에 대한 검증 결과, 세 손실 함수 모두 필수 요소임을 확인하였다.

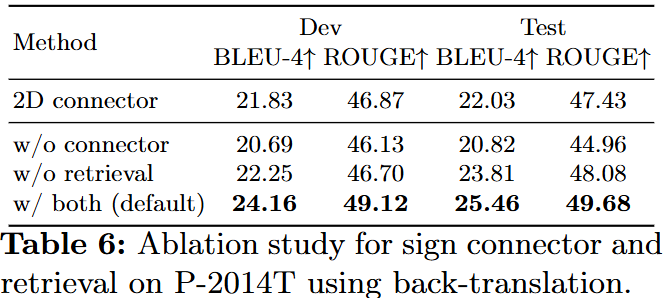
제안한 sign connector ablation 결과, 제안한 기본 방식이 다른 변형보다 낮은 오차를 보였으며, 3D 공간에서 공동 발화를 모델링하는 것이 성능 향상에 필수적임을 확인하였다. 또한 connector나 retriever를 제거하면 성능이 크게 저하되어, 두 모듈 모두 Spoken2Sign 시스템의 핵심 구성 요소임을 검증하였다.