CVPR 2025
ArXiv
Github
Seokhyeon Hong, Chaelin Kim, Serin Yoon, Junghyun Nam, Sihun Cha, Junyong No
Introduction
캐릭터 애니메이션은 다양한 컴퓨터 그래픽스 및 비전 응용 분야에서 핵심적인 역할을 한다. 그러나 keyframing이나 motion capture와 같은 전통적인 방식은 많은 수작업이 필요해 비효율적이라는 단점이 존재한다. 최근에는 diffusion 모델을 활용한 text-to-motion(T2M) 기법이 등장하여, 직관적이고 효율적인 애니메이션 워크플로우를 가능하게 하고 있다.
하지만 기존 diffusion 기반 모델은 ①포즈를 하나의 벡터로 표현하고 주로 temporal 관계에 집중하여, skeletal joints 간의 spatial 상호작용을 충분히 반영하지 못한다. 또한 ②문장을 조건으로 활용할 때 하나의 벡터로 압축하는 경우가 많아, word-level의 중요한 단서를 놓칠 수 있다. 이러한 단순화로 인해 생성된 결과에서 세부 정보가 손실될 수 있으며, 따라서 복잡한 골격–시간–텍스트 간 의존성을 충실히 포착할 수 있는 모델의 필요성이 강조된다.
또한 저자들은 의미 있는 representation을 학습하는 것이 zero-shot downstream 작업을 가능하게 하는 핵심 요소임을 강조한다. 이를 위해 pre-trained attention 모듈을 활용할 수 있으나, 기존 motion generation 모델은 일반적으로 해석 가능하고 조작 가능한 중간 표현을 결여하고 있다. 이는 앞서 언급한 모션과 텍스트 특징의 과도한 단순화에서 기인하며, 두 요소 간의 풍부한 상호작용을 제한한다.
일부 기존 방법들은 manual mask, optimization, fine-tuning과 같은 기법을 통해 사전 학습된 모델을 활용하였으나, 이러한 접근은 추가적인 노력, 시간, 비용이 요구되어 모델의 versatility와 flexibility을 저해할 수 있다.
저자들은 기존의 문제를 해결할 수 있는 T2M 모델인 skeleton-aware latent diffusion(SALAD)를 제안한다. 먼저 variational autoencoder(VAE)를 활용하여 motion latent space을 구성하며, 이 과정에서 spatial과 temporal 차원을 분리한다. 인접 관절과 프레임 간의 상호작용을 촉진하기 위해 skeleto-temporal convolution layer를 적용하고, 샘플링 효율을 높이기 위해 skeleto-temporal pooling layer를 도입하여 compact한 representation을 생성한다.
이후 diffusion 모델을 학습하여 텍스트에 조건화된 모션 특징을 생성한다. denoiser 학습 시에는 skeletal and temporal attention blocks을 함께 사용하여 skeleto-temporal coherence을 확보한다. 또한 cross-attention을 통해 word와 모션 잠재 표현의 skeleto-temporal units 간의 fine-grained interactions을 포착한다.
motion generation을 넘어, 저자들은 pre-trained SALAD 모델을 활용한 attention-based zero-shot text-driven motion editing 기법을 제안한다. 이 방법은 추가적인 optimization나 fine-tuning을 요구하지 않는다. 저자들은 SALAD의 intermediate cross-attention map이 텍스트와 모션 특징 간의 관계를 포착한다는 점에 착안하여, 이를 modulation함으로써 사용자가 텍스트 입력만으로 학습 과정 없이 모션을 편집할 수 있음을 보였다. 또한, motion-specific 작업을 위한 새로운 attention modulation 방법을 제안하여 본 접근 방식의 실질적 잠재력을 입증하였다.
Method
본 연구는 Text-to-Motion task를 다루며 text prompt가 들어왔을 때 모션을 생성하는 것을 목표로 한다.
Skeleton-aware VAE

저자들은 skeleton-aware motion feature를 학습하기 위해 VAE 아키텍처를 설계하였다. 이 구조는 skeleto-temporal convolution (STConv)과 pooling layer로 구성되며, STConv는 핵심 모듈로서 관절과 프레임 차원을 분리하면서 각 차원 내 인접 구성 요소 간 정보 교환을 가능하게 한다.
모션 시퀀스를 skeleto-temporal하게 분리하는 것은 정교한 모션 모델링을 가능하게 하지만, 관절 차원을 추가 도입함에 따라 데이터 공간이 확장되고, 이는 확률 미분 방정식(SDE)을 고차원 공간에서 풀어야 하는 디퓨전 모델의 계산 복잡도를 크게 증가시키며 curse of dimensionality 문제를 초래한다. 이를 해결하기 위해 저자들은 skeleto-temporal pooling(STPool) layer를 인코더에 적용하여 latent space를 효과적으로 압축하고, 반대로 디코더에서는 skeleto-temporal unpooling (STUnpool) layer를 적용하여 원래 모션을 복원할 수 있도록 하였다.
Encoder.
저자들은 motion seqence $m_{1:N}$를 각 pose vector를 joint-wise로 분리한 뒤 이를 관절 단위의 MLP layer를 거쳐 $\mathbf{h} \in \mathbb{R}^{N \times J \times D}$를 얻는데, 이때 $N$, $J$, $D$는 각각 프레임 수, 관절 수, latent dim을 의미한다. 이후 $\mathbf{h}$는 STConv layer를 통과한다:
$$\text{STConv}(h) := \text{SkelConv}(h) + \text{TempConv}(h) $$
구체적으로 STConv는 관절 차원에 대한 graph convolution network(SkelConv)와 프레임 차원에 대한 1D convolution network(TempConv)의 합으로 이루어진다.
STConv 출력에 Skeleto-temporal Pooling (STPool) 레이어를 적용하여 latent space의 차원을 줄이게 된다.
$$\text{STPool}(h) := \text{TempConv(SkelPool(h))} $$
이는 joint 차원와 temporal 차원에 각각 pooling을 하는 구조이다.
결과적으로 latent vector $\mathbf{z} \in \mathbb{R}^{N' \times J' \times D} $를 생성하며 $N' < N$ 줄어든 프레임 수 및 $J' < J$ 줄어든 관절 수이다. 저자들은 $J'$를 7개의 원자 관절만 유지하도록 하였다.
Decoder.
VAE decoder는 latent vector $z$를 입력받아 원래 motion으로 복원한다. 이는 encoder와 대칭적인 구조로 구성되었으며 최종적으로 MLP layer를 거쳐 $\hat{m}_{1:N}$를 생성한다.
Training.
VAE는 다음과 같은 objective로 학습된다:
$$L_{VAE} = L_m + \lambda_{pos}L_{pos} + \lambda_{vel}L_{vel} + \lambda_{kl}L_{kl} $$
- $\mathbf{L_m}$: motion features에 대한 L1 Reconstruction loss.
- $\mathbf{L_{pos}}$: joint positions에 대한 L1 Reconstruction loss.
- $\mathbf{L_{vel}}$: joint velocities에 대한 L1 Reconstruction loss.
- $\mathbf{L_{kl}}$: Kullback–Leibler (KL) divergence regularization
Skeleton-aware Denoiser

Network Architecture.
Diffusion model은 positional embedding, MLP based encoder–decoder, 그리고 여러 개의 Transformer layer로 구성된다. 각 Transformer layer는 크게 세 가지 attention 블록으로 나눠진다:
- TempAttn: 프레임 간 상호작용을 모델링
- SkelAttn: 관절 간 상호작용을 모델링
- CrossAttn: 모션과 텍스트 간 상호작용을 모델링
이 블록들은 residual connection, layer normalization(LN), FiLM(디퓨전 타임스텝에 따라 feature modulation)을 포함한다. 또한 layer stack 안에는 skip connection도 들어간다. 즉, 한 타임스텝 $t$에서 latent는 TempAttn → SkelAttn → CrossAttn을 순차적으로 거치면서 업데이트되며, CrossAttn에는 pre-trained된 CLIP text encoder가 사용되고 학습 중에는 freeze된다.
Diffusion Parametrization.
본 저자들은 diffusion training objective로 velocity($v$)를 예측한다. 이는 노이즈($\epsilon$)와 샘플($x$)을 조합하여 다음과 같이 정의할 수 있다:
$$v_t = \alpha_t \epsilon - \sigma_t x $$
기존 $\epsilon$-predict과 $x$-predict 방식이 diffusion에서 널리 사용되지만, $v$-predict 방식은 이 두 파라미터화를 암묵적으로 결합하여 안정성 및 성능을 향상시킨다.
Training and Inference.
본 저자들은 l2 loss를 사용하여 학습을 수행하였으며, classifier-free guidance (CFG) 또한 적용하였다. 추가적으로 Inference 시 DDIM sampling을 사용해 생성 품질을 유지하면서 스텝 수를 줄였다.
Zero-shot Text-driven Motion Editing.
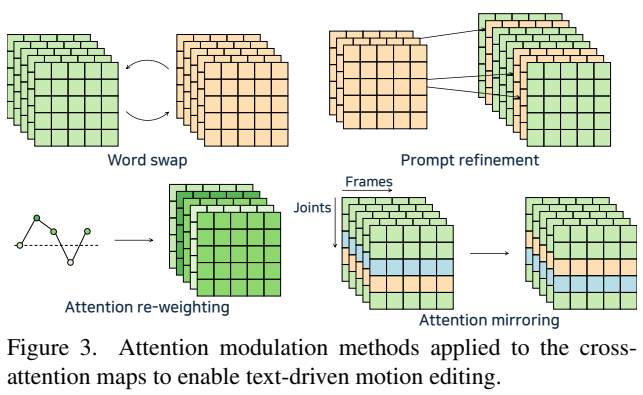
저자들은 pretrain된 SALAD 모델을 이용하여 zero-shot에서 모션 편집을 가능하게 하는 attention modulation method를 제안한다. 추가적인 해석을 하자면 cross-attention map은 텍스트가 모션의 어느 신체 부위와 어느 시점의 역학을 활성화시키는지 semantic 관계를 효과적으로 포착할 수 있기에 이러한 editing을 가능하게 한다.
본 논문에서는 word swap, prompt refinement, attention re-weighting, attention mirroring의 4가지 주요 전략을 제시하였다.
word swap: 대상 프롬프트의 설명을 통합하면서도 원본 모션의 움직임을 유지한다. 구체적으로 초기 디노이징 단계에서는 원본 프롬프트의 어텐션 맵을 주입하여 전체 구성을 잡고, 나중 단계에서는 대상 프롬프트의 어텐션 맵으로 전환하여 세부 사항을 다듬는다.
Prompt Refinement: 원본 텍스트에 새로운 토큰을 추가하여 모션에 세부 정보를 추가한다. 대상 프롬프트의 attention map을 얻은 후 기존 토큰에 해당하는 어텐션 값은 원본 어텐션 맵으로 덮어써서 공통 정보를 보존한다.
Attention Re-weighting: 사용자가 선택한 특정 단어에 할당된 어텐션 값에 스케일링 매개변수를 적용하여 모션에 대한 영향력을 증폭하거나 감소시킨다.
Attention Mirroring: 왼팔과 오른팔처럼 대칭적인 신체 부위 간의 어텐션 값을 교환하여 좌우 반전된(mirrored) 모션을 생성한다.
Experiments
본 논문은 HumanML3D와 KIT-ML venchmark dataset에서 평가하였으며, 두 데이터셋 모두 mirroring을 통해 augment하였다.
Quantitative 평가 결과. SALAD는 HumanML3D 및 KIT-ML 두 주요 벤치마크 데이터셋에서 이전 방법들과 비교하여 뛰어난 성능을 입증하였다.

Qualitative 평가 결과. 입력된 모든 텍스트 설명을 일관되게 모션에 반영하였다.

Effectiveness of Skeleton-aware Latent Space. 모션 특징을 골격-시간적으로 압축하는 Skeleton-aware VAE의 효율성을 MoMask와 ParCo에서 사용된 기존 VAE 구조와 비교하였다. 이는 Skeleton-aware 잠재 공간이 의미 있는 모션 잠재 공간을 구축하는 데 효과적임을 입증하였다.

ST-Latent 및 CrossAttn의 중요성. Denoiser의 성능에 있어 핵심 구성 요소인 ST-Latent와 Cross-Attention의 중요성을 검증하였다. 실험 결과. skeleto-temporal적으로 구조화된 잠재 공간 내에서 Cross-Attention을 통한 텍스트와 모션 간의 풍부한 정보 교환이 Denoiser 성능 향상에 필수적임을 보인다.

CFG Weights. CFG 가중치 가 증가함에 따라 성능은 향상되었으나, 과도하게 높을 경우 오히려 성능이 저하되었다. 실험 결과, w=7.5가 생성 품질과 텍스트 프롬프트 정합성 간의 균형을 이루는 최적의 값으로 나타났다.

Zero-shot Text-driven Motion Editing. 아래 그림과 같이 의미적으로 대응되는 적절한 프레임과 신체 부위에 높은 어텐션이 할당되었다. 이러한 관찰을 바탕으로, 저자들은 cross-attention 조정만으로도 추가 학습 없이 모션 editing이 가능함을 보였다.

저자들은 이에 대해, SALAD 모델의 명시적인 골격–시간–텍스트 상호작용 모델링이 효과적인 표현 학습을 가능하게 했으며, 이를 통해 생성과 편집 모두에서 fine-grained한 control이 가능함을 시사하였다.



