ICCV 2025
arxiv
Git project
Ronglai Zuo, Rolandos Alexandros Potamias, Evangelos Ververas, Jiankang Deng, Stefanos Zafeiriou
Introduction
수어(Sign language)는 청각 장애인 및 난청인의 커뮤니티에서 사용되는 주요 의사소통 수단으로, 그들만의 고유한 언어적 특징을 가지고 있다. 연구자들은 구어와 수어 사이의 장벽을 완화하기 위해 수어 번역(Sign Language Translation, SLT)과 수어 생성(Sign Language Generation, SLG) 두 가지 방향으로 접근해 왔다.
하지만 SLT와 달리, 저자들은 SLG에서의 언어 모델(Language Models, LMs) 연구가 상대적으로 부족하다고 지적한다. 기존 대부분의 연구들은 SLG를 시각적 콘텐츠 생성이나 모션 문제로 접근해 GANs 또는 디퓨전 모델을 사용했다. 그러나 이는 수어의 언어적 본질을 간과했고, 그 결과 성능은 최적 이하(suboptimal)에 머물렀으며, 사전 학습 언어 모델(Pre-trained Language Models, PLMs)이 제공할 수 있는 범용성과 확장성의 이점을 제대로 활용하지 못했다.
특히 수어는 구어와 근본적으로 언어적 특성과 이산적 구조(discrete structure)를 공유하기 때문에, 자기 회귀 언어 모델링(autoregressive language modeling) 기법이 필수적이라고 강조한다.
SLG를 언어 모델링(language modeling)에 적용하기 위해서는 수어를 이산적 토큰(discrete tokens)으로 매핑하는 것이 필수적이다. 일반적으로 글로스(gloss)를 중간 표현으로 사용하지만, 이는 노동 집약적일 뿐만 아니라 미리 정의된 정보 병목(information bottleneck)을 강제해 수어의 풍부한 의미를 담는 데 한계가 있다.
이러한 한계를 극복하고 수어의 다중 단서(multi-cue) 특성을 더 잘 반영하기 위해, 저자들은 VQ-VAE(Vector Quantized-Variational Auto-Encoder) 기반 토크나이저를 활용한다. 이 방식은 연속적인 수어 동작을 상체, 왼손, 오른손으로 나눠 각각 이산적 토큰으로 매핑한다. 하지만 기존 접근은 디코딩 과정에서 각 신체 부위를 따로 처리해 단계가 3배로 늘어나 비효율적인 추론을 초래한다. 이를 해결하기 위해 저자들은 여러 신체 부위 정보를 실시간으로 융합하면서 한 번에 여러 토큰을 예측할 수 있는 멀티헤드 디코딩(Multi-head decoding) 방법을 제안한다.
또한 수어 데이터셋이 제한된 어휘 크기(vocabulary size)를 갖는 문제를 보완하기 위해, 저자들은 다국어 언어 모델(multilingual LM)을 도입하여 더 넓고 다양한 표현을 다룰 수 있도록 한다. 이를 위해 미국, 중국, 독일 수어 데이터셋을 통합해 학습에 활용 가능한 다국어 수어 데이터셋을 구축하였다.
추가적으로, 저자들은 RAG(Retrieval-Augmented Generation) 방식에서 영감을 받아 Retrieval-enhanced SLG를 제안한다. 이 접근은 검색된 사전 수어의 동작 토큰을 언어 모델링의 추가 조건으로 활용한다. 이를 통해 사전 수어의 정확성은 살리면서도, 사전을 그대로 복사해 출력할 때 생기는 부자연스러움은 효과적으로 해소할 수 있다.
Methodology

위 그림과 같이 본 연구의 전체 접근은 크게 Decoupled Tokenizer(DETO)와 Autoregressive Multilingual Generator(AMG)로 구성된다. DETO는 연속적인 수어 동작과 신체 부위별 이산 토큰 간의 매핑을 학습하며, AMG는 제안한 Multi-head decoding 전략을 기반으로 텍스트 입력과 검색된 사전 수어에 조건부로 자기회귀적(autoregressive) 모션 토큰을 생성하도록 학습된다.
Data Preparation.
수어 데이터셋의 경우 3D annotation이 제공되지 않기 때문에, 저자들은 직접 SMPL-X pose를 구축해 학습용 데이터셋을 구성하였다. 이를 위해 SOTA 3D pose estimation 기법을 활용한 2단계 접근을 통해 중국 수어(CSL-Daily)와 독일 수어(Phoenix-2014T)에 대해 고정밀 SMPL-X 포즈를 추출하였다.
구체적으로, OSX를 이용해 대략적인 3D 신체 포즈를 추정하고, WiLoR을 통해 정확한 3D 손 포즈를 추출한다. 하지만 OSX는 팔 포즈를 정확히 포착하지 못하는 경우가 많아, 이전 연구를 따라 상체 관절 회전(upper body joint rotations)을 보정한다. 이 과정은 추정된 관절과 Mediapipe로 탐지된 2D 관절 키포인트 간의 re-projection loss을 최소화하는 방식으로 수행된다. 이를 통해 정확한 whole-body annotation을 확보할 수 있다.
최종적으로 각 수어 동작 시퀀스는 $S \in \mathbb{R}^{T \times d}$로 표현되며, 여기서 $T$는 시퀀스의 길이, $d = 133$는 SMPL-X 파라미터 개수를 나타낸다. 이 안에는 상체 관절 11개, 손 관절 30개 그리고 표정 파라미터 10개가 포함된다.
Decoupled Tokenizer.
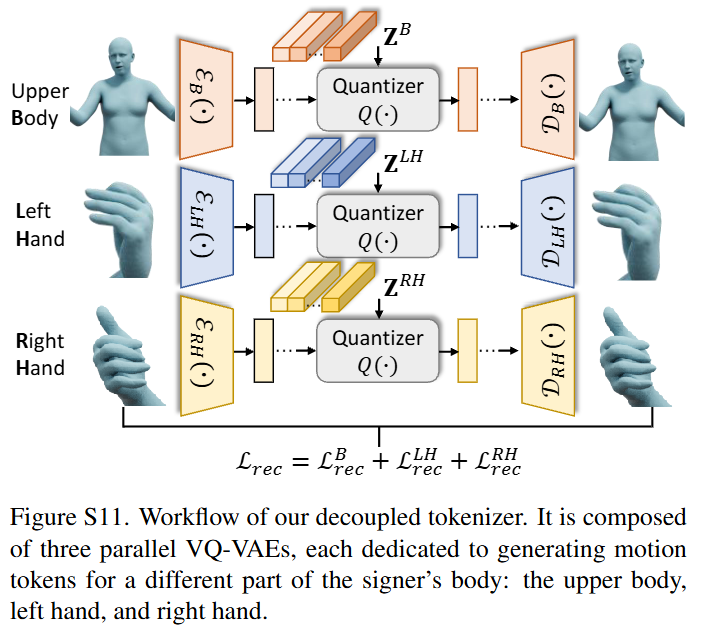
수어는 multi-cue property을 가지는데, 이는 의미가 신체 움직임과 손동작을 통해 동시에 전달된다는 것을 의미한다. 저자들은 이에 착안해 세 개의 VQ-VAE로 구성된 decoupled tokenizer를 활용하여 상체와 양손을 독립적으로 모델링한다.
구체적으로 수어 모션인 $S \in \mathbb{R}^{T \times d}$가 주어지면 SMPL-X의 kinematic tree를 기반으로 이를 세 부분의 모션 시퀀스 $S^{p} \in \mathbb{R}^{T \times d_{p}}$로 분해한다. 여기서 $p \in {B, LH, RH}$는 각각 상체, 왼손, 오른손을 의미한다.
이후 위 그림과 같이 각 부분에 대해 VQ-VAE를 구축하며 이는 인코더 $E_{p}(\cdot)$, 디코더 $D_{p}(\cdot)$, 코드북 $Z^{p} \in \mathbb{R}^{N_{Z}^{p} \times C}$으로 구성된다. 인코더는 1D-CNN으로 구성되며, 각 모션 시퀀스를 latent space로 투영한다. 이후 quantizer를 통해 코드북에서 가장 가까운 이웃을 검색하여 discrete token을 얻는다:
$$ \hat{z}{i}^{p} = Q(s{f,i}^{p}) = \arg\min_{z_{j} \in Z^{p}} | s_{f,i}^{p} - z_{j} |{2}, \quad j \in [1, N{Z}^{p}] $$
얻어진 토큰 시퀀스를 디코더$D_{p}(\cdot)$에 입력하여 원래 모션을 복원하며 다음 objective function을 통해 학습된다.
$$\mathcal{L}{vq}^{p} = \mathcal{L}{rec}^{p} + \mathcal{L}{emb}^{p} + \mathcal{L}{com}^{p}$$
- $\mathcal{L}{rec}^{p} = | \hat{S}^{p} - S^{p} |{2}^{2}$: reconstruction loss
- $\mathcal{L}_{emb}^{p}$: embedding loss
- $\mathcal{L}_{com}^{p}$: commitment loss
Autoregressive Multilingual Generator.
위로부터 얻어진 이산적인 수어 표현을 사용한다면, 수어의 이산적인 특성을 활용하면서도 PLM을 이용하여 텍스트 생성과 유사한 방식으로 SLG에 접근할 수 있다.
Integrated Vocabulary. 먼저 저자들은 신체 부위 별로 얻은 이산 토큰들을 모아 부위 별 모션 vocabulary를 구성한다:
$$\mathcal{V}{m}^{p} = {<p_i>}{i=1}^{N_{Z}^{p}}$$
전체 모션 vocab은 $\mathcal{V}{m} = {\mathcal{V}{m}^{B}, \mathcal{V}{m}^{LH}, \mathcal{V}{m}^{RH}}$로서 세 가지 부위별 어휘의 결합으로 정의된다. 또한 $\mathcal{V}_{l} = {\langle ASL\rangle, \langle CSL\rangle, \langle DGS\rangle}$의 언어 식별 토큰을 도입하여 목표 수어에 대한 정보를 제공한다. 최종적으로 generator를 위한 vocab은 $\mathcal{V} = {\mathcal{V}{l}, \mathcal{V}{m}, \mathcal{V}_{t}}$로 정의된다.

Parallel Decoding. 앞서 언급했듯, 일반적인 순차적 생성 방식을 적용할 경우 3번의 디코딩 단계가 필요하기 때문에 이는 비효율을 초례한다. 따라서 저자들은 디코딩 속도를 높이기 위해 목표 시퀀스 $Y$를 세 개의 부위 단위 시퀀스 $Y^{p} = {y_{1}^{p}, \ldots, y_{K}^{p}}$로 분해한다. 또한 세 개의 LM 디코더를 weight shared로 구성하여 각 신체 부위를 담당하도록 한다.
또한 각 신체 부위 정보를 디코더에 제공하기 위해, 기존 언어 식별 토큰을 새로운 특수 토큰 집합 $\mathcal{V}_{l} = {\langle \text{Lang}_p \rangle}$로 대체한다. 이때 Lang는 목표 언어, p는 신체 부위를 의미한다.
위 그림 (b)에서 보이듯이 세 개의 병렬 디코딩 과정은 이러한 특수 토큰 중 하나에서 시작되며 다음과 같이 공식화 된다:
$$P(Y \mid h_{en}) = P(Y^{B}) P(Y^{LH}) P(Y^{RH}) =$$
$$\prod_{k=1}^{K} P(y_{k}^{B} \mid y_{<k}^{B}) ; \prod_{k=1}^{K} P(y_{k}^{LH} \mid y_{<k}^{LH}) ; \prod_{k=1}^{K} P(y_{k}^{RH} \mid y_{<k}^{RH})$$
이러한 병렬 구조는 효율성을 크게 높여주지만, 각 부위를 완전히 독립적으로 가정하기 때문에 상호 의존성을 반영하지 못해 성능이 suboptimal에 머무를 수 있다.
Multi-Head Decoding. 따라서 저자들은 각 신체 부위 간 융합을 균형 있게 달성하기 위해 Multi-head decoding 전략을 제안한다. 위 그림 (c)와 같이 fully connected layers로 이뤄진 3개의 modeling head를 decoder 뒤에 구성하였으며 각 단계마다 상체, 왼손, 오른손의 모션 토큰을 동시에 예측한다.
또한 각 단계에서 디코더 입력은 서로 다른 신체 부위 토큰 임베딩의 가중 평균으로 수정된다. 구체적으로 상체, 왼손, 오른손 토큰 임베딩 $\mathbf{E}^{B}, \mathbf{E}^{LH}, \mathbf{E}^{RH}$은 다음과 같이 정의된다:
$$\mathbf{E} = (1 - 2\lambda)\mathbf{E}^{B} + \lambda \mathbf{E}^{LH} + \lambda \mathbf{E}^{RH}$$
이때 $\lambda \in (0, 0.5)$는 손 임베딩의 가중치를 조절하는 하이퍼파라미터이며 궁극적으로 디코딩 과정은 다음과 같이 공식화 된다:
$$P(Y \mid h_{en}) = \prod_{k=1}^{K} P(y_{k}^{B,LH,RH} \mid y_{<k}^{B,LH,RH}) \tag{4}$$
Training and Inference. 학습은 일반적인 cross-entropy loss로 학습된다. 추론 시에는 단순한 greedy decoding 알고리즘을 사용하여 가장 높은 확률을 갖는 토큰을 선택한다. 또한 병렬 디코딩과 멀티헤드 디코딩의 경우 어느 헤드나 디코더가 $EOS$를 예측하는 순간 추론이 종료된다, 최종적으로 얻어진 토큰 시퀀스는 각 부위에 해당하는 디코더에 입력되어 수어 모션을 복원하게 된다.
Retrieval-Enhanced SLG.

저자들은 RAG(Retrieval-Augmented Generation) 방식에서 영감을 받아 외부 수어 사전을 활용함으로써 생성된 수어의 fidelity를 향상시킨다. 그림에 나타난 것처럼, 각 타겟 수어에 대해 단어 수준의 수어 사전을 구축하며, 이를 위해 기존 isolated sign language recognition 데이터셋과 온라인 리소스를 활용한다. 이후 pose fitting pipeline을 거쳐 사전에 포함된 각 RGB 비디오를 SMPL-X pose로 변환한다.
다음으로, 학습된 decoupled tokenizer를 적용하여 포즈를 discrete token으로 매핑한다. 결과적으로 dict은 사중쌍 $\{(w,m^B,m^{LH} ,m^{RH} )\}|$의 집합으로 표현된다. 만약 한 단어에 대해 여러 수어 인스턴스가 존재할 시, 토크나이저를 통과한 뒤 reconstruction error가 가장 낮은 인스턴스만을 유지한다.
후에 텍스트 입력 $X$이 주어지면 사전에 일치하는 모든 단어와 대응되는 토큰을 수집한다. 최종적으로 원문 텍스트와 검색된 모션 토큰을 연결하여 프롬프트를 생성한 뒤 이를 LM encoder에 입력되어 hidden state를 생성한다.
Experiments
Implementation Detail.
- DETO: 코드 개수의 경우 신체는 96, 왼손/오른손은 196개로 설정하였으며, 코드 차원의 경우 512로 설정하였다. GPU 당 batch는 320으로 총 500 에폭으로 학습하였다.
- LM: LM으로 mBART-large-cc25를 사용하였으며 부위별 토큰 임베딩의 균형을 위해 $\lambda=1/3$으로 설정하였다. GPU 당 batch는 32로 다국어 수어 데이터셋에 대해 150 epoch 동안 fine-tuning을 수행하였다.
Comparison with State-of-the-Art Method.

Quantitative Comparison. 위의 Tabel 1 같이 저자들은 기존 방법들 대비 모든 평가 지표에서 경쟁력 있는 성능을 달성하였다. (저걸 하나하나 다시 다 구현했다는 것이 key.. GT가 없어서 이 분야 연구가 쉽지 않아 보임)


Qualitative Comparison. 위 그림과 같이 SOKE는 질적 비교 결과 높은 시각적 품질을 달성하였다. (GT 자체도 이상하게 뽑힌 것이 key임..)
Ablation Study.

Decoding Method. 디코딩 방식에 대해 비교한 결과, 기존 sequential 한 방식의 경우 높은 Latency를 보이며 비효율성을 입증하였다. 또한 Parallel의 경우 추론 시간을 크게 줄였지만 각 신체 부위 별 모션 토큰 간 정보 융합이 부족하여 JPE 점수가 낮은 것을 확인할 수 있다.
Sign Retrieval . SLG 기반 접근 방식의 경우 추가적인 생성 조건으로 인해 생성 수어의 정확성을 크게 향상시킨 것을 확인할 수 있다.

Scalability with Multilingual Data. 위 테이블 결과 다국어 데이터를 통합할수록 생성 성능이 크게 향상되며 이는 제안된 접근법의 scalabitity를 입증한다.

Decoupled Tokenizer. 각 special codebook 적용 시 일관되게 성능이 개선되는 것을 보아 분리형 토크나이저의 성능을 입증한다.


