CVPR 2025
https://arxiv.org/abs/2504.04956
Jihyun Lee, Weipeng Xu, Alexander Richard, Shih-En Wei, Shunsuke Saito, Shaojie Bai, Te-Li Wang, Minhyuk Sung, Tae-Kyun Kim, Jason Saragih
Meta
Introdution

Egocentric human motion estimation은 게임이나 AR/VR과 같은 응용 프로그램에서 현실감 있는 경험을 제공하는 데 있어 필수적인 기술이다. 예컨대 가상 환경 내에서 인간 간 소통이 이뤄지는 상황에서는, 전신(E.g. 몸, 손)의 동작이 얼마나 정확하게 추정되는가에 따라 현실감의 수준이 달라진다. 특히 위의 그림(b)와 같이 손가락과 미묘한 자세 변화는 전달하고자 하는 메시지에 큰 영향을 줄 수 있다.
따라서 정확하고 현실적인 Egocentric whole-body motion estimation을 가능하게 하는 real-time 방법은 중요하다. 하지만 그간 연구들의 경우 accuracy와 speed 측면 모두에서 만족스러운 성과를 달성하지 못하였다. 특히 이들은 대체적으로 body motion에만 집중하고 손의 중요성은 간과해왔다. 또한 기존의 body-only estimation 기법을 단순히 whole-body estimation으로 확장할 경우 suboptimal한 결과를 보이는데, 이는 입력 이미지와 출력 동작 모두에서 신체와 손이 scale 측면에서 크게 다르기 때문이다.
사실 이러한 문제를 해결하기 위해 EgoWholeMocap은 신체와 손에 특화된 specialist models을 활용함으로써 egocentric image로 부터 전신 동작을 추정하는 방법을 제안하였다. 이는 먼저 프레임 단위로 신체와 손의 pose estimation을 각각 수행한 후, 전신의 각 신체 부위 간 correlation를 모델링하기 위해 unconditional 전신 동작 prior를 사용하여 출력된 자세를 refine한다. 이 방식은 전신 동작 추정 성능을 향상시키는 데에는 효과적이지만, non-real-time이며 acausal이라는 한계가 있다. 즉, acausal diffusion-based motion prior을 활용한 iterative refinement 과정에서 미래 정보에 의존하기 때문에 실시간 추정에는 부적합하다고 저자들은 지적한다.
이에 따라 저자들은 REWIND(Real-Time Egocentric Whole-Body Motion Diffusion)라는 모델을 제안한다. REWIND는 자기중심 이미지 입력으로부터 real-time으로 고정밀 인간 동작을 추정할 수 있는 one-step diffusion 모델이다.
빠른 inference time과 높은 estimation score를 동시에 달성하기 위해, 저자들은 cascaded body-hand denoising diffusion 기법을 도입한다. 이 방식은 먼저 신체 동작을 샘플링한 후 이전에 샘플링된 상반신 동작을 조건으로 손 동작을 샘플링한다. 이러한 계단식 구조는 신체와 손 사이의 corrleation을 빠른 feed-forward 방식으로 근사 모델링할 수 있으며, 동시에 신체와 손에 특화된 추정 모델의 장점도 유지할 수 있다. 또한 이 방식은 자기중심 이미지 입력 환경에서 특히 효과적인데, 손이 자주 시야 밖에 위치하거나 가려지는 경우가 많지만, 손과 상반신 간에 의미 있는 상관관계가 많기에 손동작의 불확실성을 효과적으로 줄일 수 있다(그림 (a)).
또한 저자들은 specialist denoising diffusion model들을 causal relative-temporal Transformer 기반으로 구축한다. 이때 windowed relative-temporal attention을 사용함으로써 전체 시퀀스 길이나 absolute timestep에 무관한 temporal motion feature를 학습할 수 있다. 네트워크 학습 과정에서는 diffusion distillation 기법을 적용하여, 단일 denoising step 만으로도 real-time inference와 동시에 고품질의 output motion 수준을 유지할 수 있다.
나아가 저자들은 exemplar-based identity conditioning도 제안하는데, 이는 자세 예시를 활용해 대상의 identity를 parameterize하고, 이를 조건으로 하여 동작을 추정하는 방식이다. 이러한 방식은 기존 연구에서는 고려되지 않았지만 저자들은 실험적으로 널리 사용되는 다른 identity parameterize 방법들(E.g. 키, 뼈 길이, 형태)보다 더 효과적임을 발견하였다.
Methodology
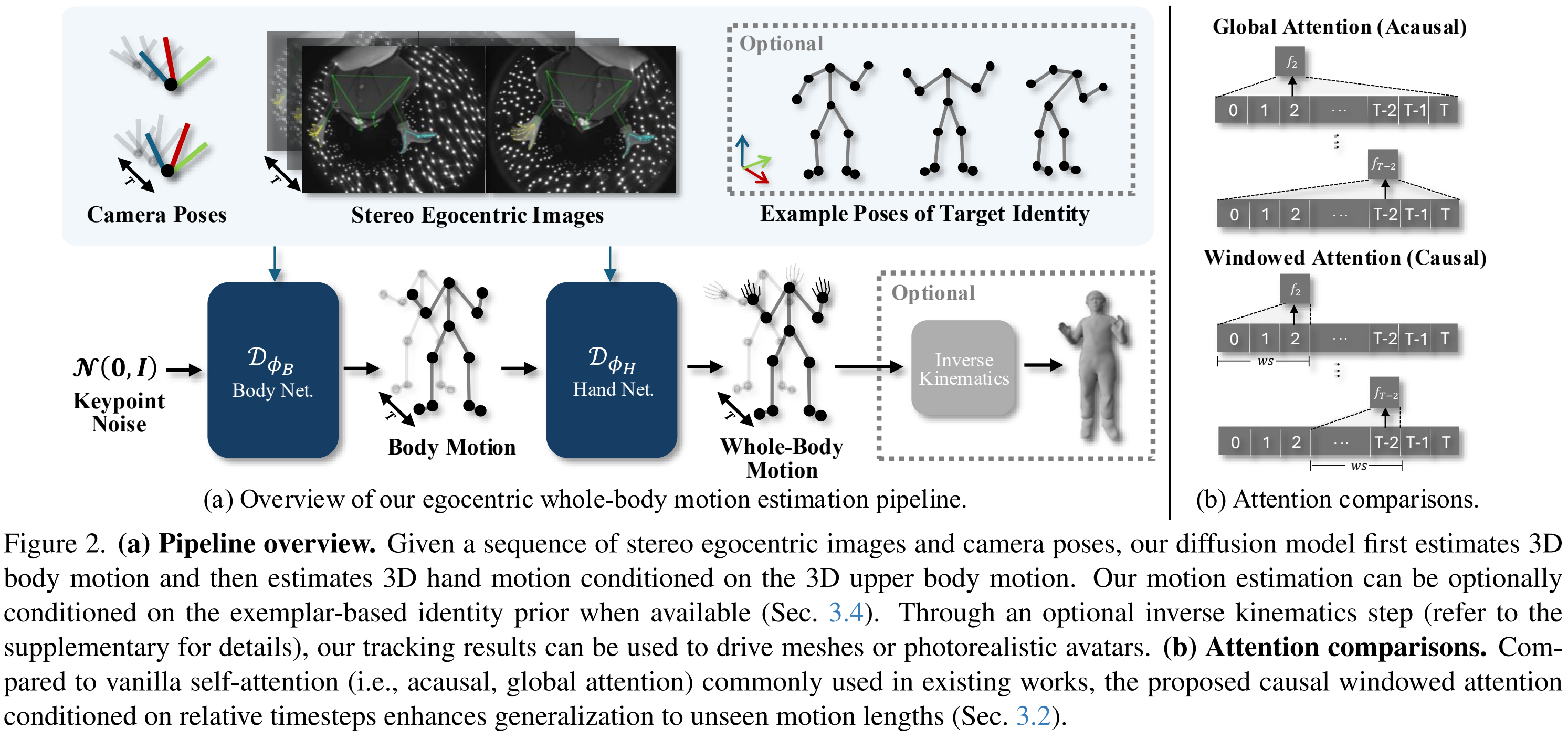
본 논문의 목표는 egocentric image 입력으로부터 real-time으로 whole-body motion을 추정하는것이다. 기존 이미지 기반 자세 또는 동작 추정 방법들의 경우 diffusion model이 occluded 혹은 out-of-view에 위치한 신체 부위에 대해 효과적임을 보여주었다. 이에 따라 저자들 또한 diffusion 기반 접근 방식을 채택하였다.
Denoising diffusion network는 egocentric observation을 조건으로 전신 동작을 모델링하며, 이는 다음과 같은 수식으로 표현된다:
$$p_{\phi}(\mathbf{J}^{1:T} \mid \mathbf{\Phi}^{1:T})$$
- $ p_{\phi}$: 디퓨전 네트워크의 파라미터 $ {\phi}$로 정의된 모델 분포
- $\mathbf{J}^{1:T}$: $T$프레임 동안의 전신 자세 시퀀스
- $\mathbf{\Phi}^{1:T}$: $T$프레임 동안의 stereo egocentirc image 및 카메라 자세를 포함한 입력 관찰 시퀀스
각 시점 $t \in (1, T)$에서 전신 자세는 $N_J$개의 3D keypoint로 표현되며, 해당 시점의 자기중심 관찰 $\mathbf{\Phi}^t$는 다음과 같이 구성된다:
$$\Phi^t = [\mathbf{I}_L, \mathbf{I}_R, \mathbf{C}_L, \mathbf{C}_R]$$
- $\mathbf{I}_{v \in {L, R}} \in \mathbb{R}^{C \times W \times H}$: 시점 $v$에서 획득한 egocentric image.
- $\mathbf{C}_{v \in {L, R}} = [\mathbf{R}_v \mid \mathbf{t}_v] \in \mathbb{R}^{3 \times 4}$: 해당 시점의 camera pose.
- $\mathbf{R}_v \in \mathbb{R}^{3 \times 3}$: camera rotation
- $\mathbf{t}_v \in \mathbb{R}^{3 \times 1}$: translation
최근 머리 장착형 장치에 사용되는 SLAM 시스템들은 높은 정확도를 달성하고 있으며, 이에 따라 카메라 자세 정보는 최근 egocentric tracking method에서 중요한 추가 입력으로 간주된다.
Cascaded Body-Hand Denoising Diffusion.
whole-body motion estimation은 신체와 손 사이의 scale 및 pose distribution의 차이로 인해 challenge하다. 이를 해결하기 위해 EgoWholeMocap이 제안되었지만, 앞서 언급한 바와 같이 ①inference speed가 느리며, ②unconditional motion prior로 인해 일관성을 갖는 동작을 예측하지 못하는 두 가지 주요 한계가 존재한다.
저자들은 이를 해결하기 위해 cascaded body-hand denoising diffusion을 제안한다. 이 기법의 핵심 아이디어는 body motion을 예측한 후, 추정된 3D upper body motion을 codition으로 하여 hand motion을 추정하는 것이다. 이러한 접근은 3D 상반신과 손 자세 간의 의미 있는 상관관계가 존재한다는 기존 연구에 영감을 받았다.
이러한 cascading approach는 신체와 손 사이의 근사된 상관관계를 빠르고 feed-forward 방식으로 포착할 수 있게 하며, 동시에 기존 연구처럼 신체와 손에 특화된 추정 기법의 장점도 유지할 수 있다. 이러한 접근은 특히 egocentric hand estimation에 효과적인데, 실제로 손이 시야 밖에 위치하거나 다른 신체 부위에 occluded 될 수 있어 입력 자체가 ambiguous한 경우가 많다. 반면 상반신 3D 자세의 경우 일반적으로 더 안정적인 관측을 할 수 있어 이를 조건으로 할 시 손동작을 정밀하게 추정할 수 있다.
본 연구에서 앞서 정의한 egocentric-conditioned whole-body motion distribution을 다음과 같이 재정의한다:
$$p_{\phi}(\mathbf{J}^{1:T} \mid \mathbf{\Phi}^{1:T}) \approx p_{\phi_B}(\mathbf{J}_B^{1:T} \mid \mathbf{\Phi}^{1:T}) \, p_{\phi_H}(\mathbf{J}_H^{1:T} \mid \mathbf{J}_{B_{upper}}^{1:T}, \mathbf{\Phi}^{1:T})$$
- $B$: body
- $B_{upper}$: upper body
- $H$: hand
Note. 훈련 시에는 신체 및 손에 특화된 모델(body and hand specialist models)을 각각 별도로 학습하며, 추론 시에는 학습된 두 분포로부터 cascaded 방식으로 샘플링을 수행한다.
Causal Relative-Temporal Transformer.
최근 motion diffusion model들은 Transformer encoder-based 구조가 motion distribution을 학습하는데 매우 효과적임을 보였으며, 이로 인해 해당 구조는 본 domain에서 사실상 표준이 되었다. 하지만 이러한 모델들은 일반적으로 absolute timestep encoding을 사용하는 vanilla self-attention 기반으로 고정 길이의 동작 시퀀스만을 생성할 수 있다. 이러한 구조는 학습 시 보지 못한 길이의 동작 시퀀스의 일반화 측면에서의 제한이 존재한다. 이러한 문제들을 해결하기 위해 여러 기법들이 제안되어 왔지만 이들은 공통적으로 temporal extrapolation을 수행하기 위해 미래 정보에 의존해야 한다.
본 연구에서는 causal relative-temporal Transformer를 도입함으로써, 전체 동작 길이나 미래 프레임에 무관하게 temporal 특징을 학습할 수 있게 한다. 이 구조는 fully causal 하며, 임의의 동작 길이에 대해 본질적으로 일반화 능력을 갖는다. 핵심 아이디어는 RoPE(Rotary Positional Encoding)을 도입하여 입력 토큰 간 상대적인 temporal distance에 따라 attention score를 조정하고 각 토큰의 어텐션 범위를 과거 프레임 $ws \in \mathbb{N}$로 제한하는 것이다.
이를 수식적으로 보면 주어진 query, key, value에 대해 시점 $j$에서 self-attention function은 다음과 같이 정의된다:
$$\mathcal{A}(\mathbf{Q}, \mathbf{K}, \mathbf{V})_j = \frac{\sum_{i=j-ws}^{j} \mathbf{R}_j \, \theta(\mathbf{q}_j)^\top \, \mathbf{R}_i \, \rho(\mathbf{k}_i) \, \mathbf{v}_i}{\sum_{i=j-ws}^{j} \theta(\mathbf{q}_j)^\top \, \rho(\mathbf{k}_i)}$$
- $\mathbf{Q}, \mathbf{K}, \mathbf{V} \in \mathbb{R}^{D \times T}$: query, key, value 행렬
- $\mathbf{q}_i, \mathbf{k}_i, \mathbf{v}_i \in \mathbb{R}^D$: 각 time-step $i$에서의 column vector
- $θ(·) ,ρ(·)$: projection function (E.g. MLP)
- $\mathbf{R}_i \in \mathrm{SO}(D)$: time step $i$에 따라 parameter된 $D$차 rotation matrix
여기서 $ \mathbf{R}_j \, \theta(\mathbf{q}_j)$와 $ \mathbf{R}_i \, \rho(\mathbf{k}_i)$간 dot product에 기반한 attention score는 $j$번 토큰에 대한 $i$번 토큰의 상대 시간 단계에 따라 정의된 relative rotation $\mathbf{R}_{i-j}$에 의존한다. 이로 인해 출력 feature는 absolute timestep의 영향을 받지 않게 된다. 또한 각 프레임 $j$에서의 self-attention은 temporal window $[j - ws, j]$ 내의 입력 프레임에 대해서만 수행된다. 따라서 출력 특징은 고정된 개수의 과거 프레임에만 의존하며, total motion length나 미래 정보에는 의존하지 않는다.
본 연구에서는 causal relative-temporal Transformer를 기반으로 denoisin diffusion network $\mathcal{D}_{\phi_B}(\cdot)$와 $\mathcal{D}_{\phi_H}(\cdot)$를 구성한다. 신체 모델과 손 모델은 동일한 네트워크 구조를 사용하며 손 모델의 경우 상반신 조건 입력을 추가로 받는다.
네트워크는 다음의 입력을 받아 diffusion time 0에서의 keypoint $\widetilde{\mathbf{J}}^{1:T}_{0}$를 추정한다:
- $\Phi^{1:T}$: inputs a sequence of egocentric observations
- $\widetilde{\mathbf{J}}^{1:T}_{k}$: sequence of diffused keypoints
- $k$: corresponding diffusion time
먼저 $\Phi^{1:T}$로부터 frame-based feature를 추출한다. 이후 각 timestep $t$에서의 입력은 ① 2D 키포인트 및 이미지로부터 추정된 그에 대한 uncertainty scores ②camera parameters ③diffusion time 위 세 가지 요소를 포함하여 인코딩 된다. 이 conditioning feature들을 디퓨전 된 키포인트 $\widetilde{\mathbf{J}}^{1:T}_{k}$에 concatenate한 후 human skeletal graph 상에서 graph convolution을 적용하여 구조적 특징을 추출한다. 이후, causal relative-temporal Transformer를 적용하여 temporal한 feature를 추출하고 regression head를 통해 최종 동작을 추정한다.
Note. diffusion modeling에서 DDPM은 학습에, DDIM은 추정에 사용된다.
Diffusion Distillation.
저자들은 diffusion model의 multi-step sampling으로 인한 느린 inference time을 해결하기 위해, diffusion distillation 기법을 도입하여 샘플링 효율을 개선하였다. 구체적으로 original multi-step diffusion model $\mathcal{D}_{\phi}^{T}$을 single-step lightweight model $\mathcal{D}{\phi{\star}}^{S}$로 distill하며 이때 Score Distillation Sampling (SDS) loss를 사용한다.
student model이 예측한 키포인트 $\hat{\mathbf{J}}{0}^{1:T} \leftarrow \mathcal{D}{\phi_{\star}}^{S}(\widetilde{\mathbf{J}}_{K}^{1:T}, \Phi^{1:T}, K)$에 대해 distillation loss는 다음과 같이 정의된다:
$$\mathcal{L}{\text{distill}} = \left| \mathcal{D}{\phi}^{T}\left(\mathcal{E}(\hat{\mathbf{J}}{0}^{1:T}, k{\text{small}}), \Phi^{1:T}, k_{\text{small}} \right) - \hat{\mathbf{J}}{0}^{1:T} \right|{2}$$
이때 $\mathcal{E}(\cdot)$는 forward diffusion function으로, 예측된 키포인트에 소량의 노이즈를 추가하여 diffusion timestep $k_{\text{small}}$에 해당하는 상태로 변환한다.
직관적으로 위 loss는 학생 모델이 동일한 egocentric 관찰 조건 하에서 교사 모델이 가능하다고 판단하는 샘플을 생성하도록 유도한다. 이를 통해 저자들은 SOTA는 물론 30 FPS 이상의 추론 속도 또한 확보할 수 있었다.
Exemplar-Based Identity Conditioning .
제안된 방법 외에도 저자들은 출력 품질을 더욱 향상하기 위해, 동작을 수행하는 대상 identity에 대한 사전 정보를 통합하는 것이 모델에게 어떤 도움이 되는지 추가적으로 탐색하였다. 이 과정에서 저자들은 대상 identity의 소수의 예시 3D 포즈들에 조건화하여 출력 동작을 생성하는 방식인 exemplar-based identity conditioning이 매우 효과적이라는 것을 발견하였다.
형식적으로 $\{\mathbf{J}i^{\mathcal{I}}\}_{i=1,\dots,N_{\circ}}$는 $N_{\circ}$개의 동작 추정 단계 이전에 관측된 대상 아이덴티티 $\mathcal{I}$ 예시들이며, 이때 $\mathbf{J}_i^{\mathcal{I}} \in \mathbb{R}^{N_J \times 3}$로 표현된다. 이 포즈 집합은 예를 들어 대상 인물이 자연스러운 동작을 수행하는 monocular 이미지를 촬영한 뒤, 이를 바탕으로 3D 포즈를 추정하는 pose registration 과정에서 얻을 수 있다.
본 연구에서는 이미지로부터 2D 키포인트를 추정하고, 여기에 parametric body model을 피팅하여 예시 포즈를 획득한다. 이때 신장(height) 정보를 함께 사용하여 스케일 모호성을 해소한다. 이렇게 등록된 예시 포즈들은 해당 아이덴티티의 이후 모든 동작 추정 세션에서 품질 향상에 활용될 수 있으며, 기존 일부 방법에서 사용하는 scene geometry와 같은 priors보다 훨씬 획득이 간단하다.
대상 identity에 대한 예시 포즈 집합이 주어졌을 때, feature를 추출하기 위해 set encoding을 수행한다. 이를 위해 입력 포즈 각각에 대해 shared MLP-based encoder $\gamma(\cdot)$를 적용하고 얻어진 특징들을 symmetric function $\rho(\cdot)$(max-pooling)으로 다음과 같이 집계한다:
$$f_{\text{ex}}^{\mathcal{I}} = \rho\left(\gamma(\mathbf{J}_0^{\mathcal{I}}), \gamma(\mathbf{J}1^{\mathcal{I}}), \dots, \gamma(\mathbf{J}{O-1}^{\mathcal{I}}), \gamma(\mathbf{J}_O^{\mathcal{I}})\right)$$
마지막으로 $f_{\text{ex}}^{\mathcal{I}}$를 AdalN을 사용하여 본 프레임워크에 통일한다. 저자들은 실험을 통해 이 예시 기반 아이덴티티 prior가 형태(shape) 파라미터, 뼈 길이(bone length) 등 다른 identity prior보다 성능 향상이 크다는 것을 보였다.
Experiments
Dataset.
(1) ColossusEgo: 저자들이 새로 수집한 대규모 실데이터셋으로, 500명의 피험자가 HMD 기반 스테레오 카메라를 착용한 상태에서 촬영되었으며 총 2.8M 프레임으로 구성된다. 200대의 보정된 멀티뷰 카메라 시스템을 통해 고밀도 뷰포인트에서 2D 키포인트를 검출하고 triangulation 하여 정밀한 3D 전신 키포인트를 어노테이션 하였다.
(2) UnrealEgo: 합성 데이터셋으로, 원래는 body-only 목적이지만 부가적인 손 키포인트와 temporal sequence를 포함한다.
Egocentric Whole-Body Motion Estimation.
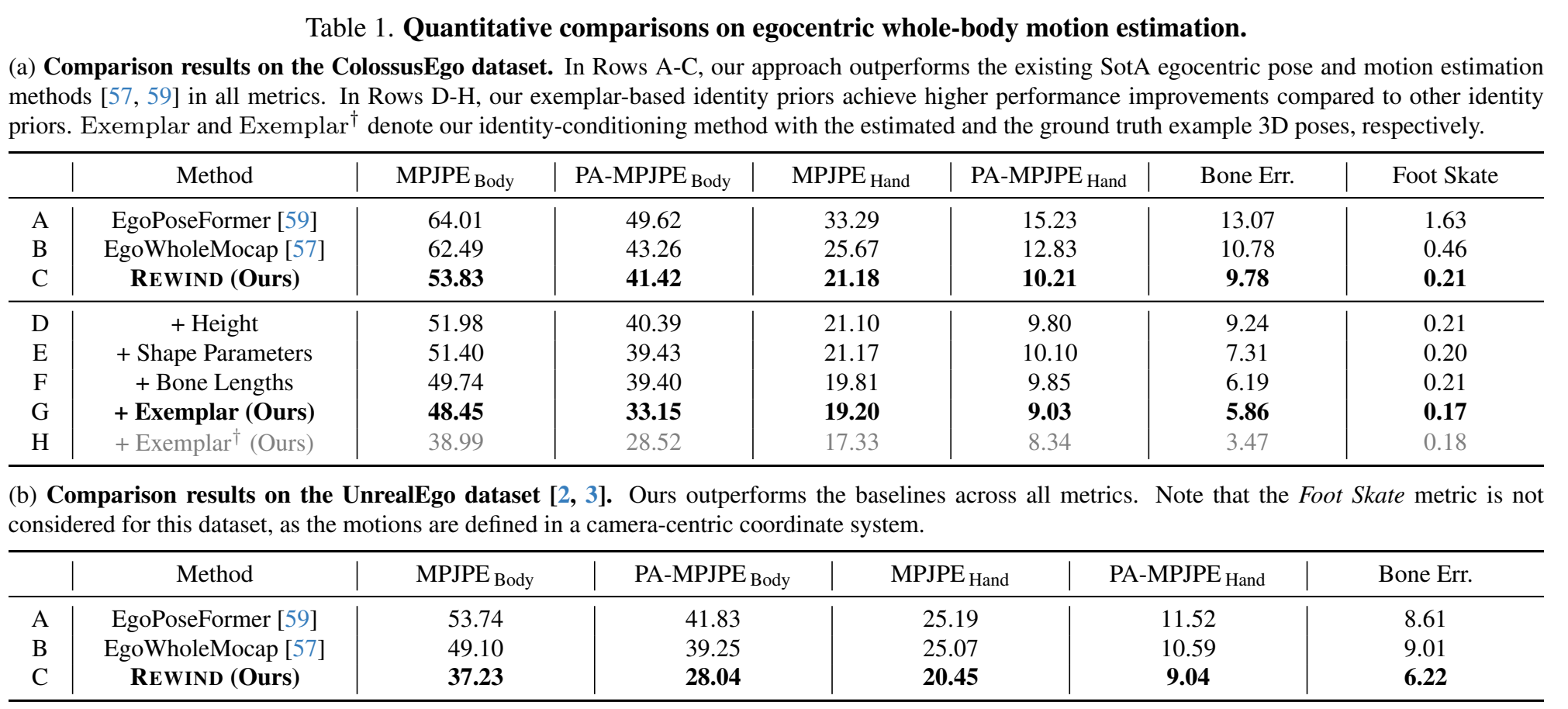
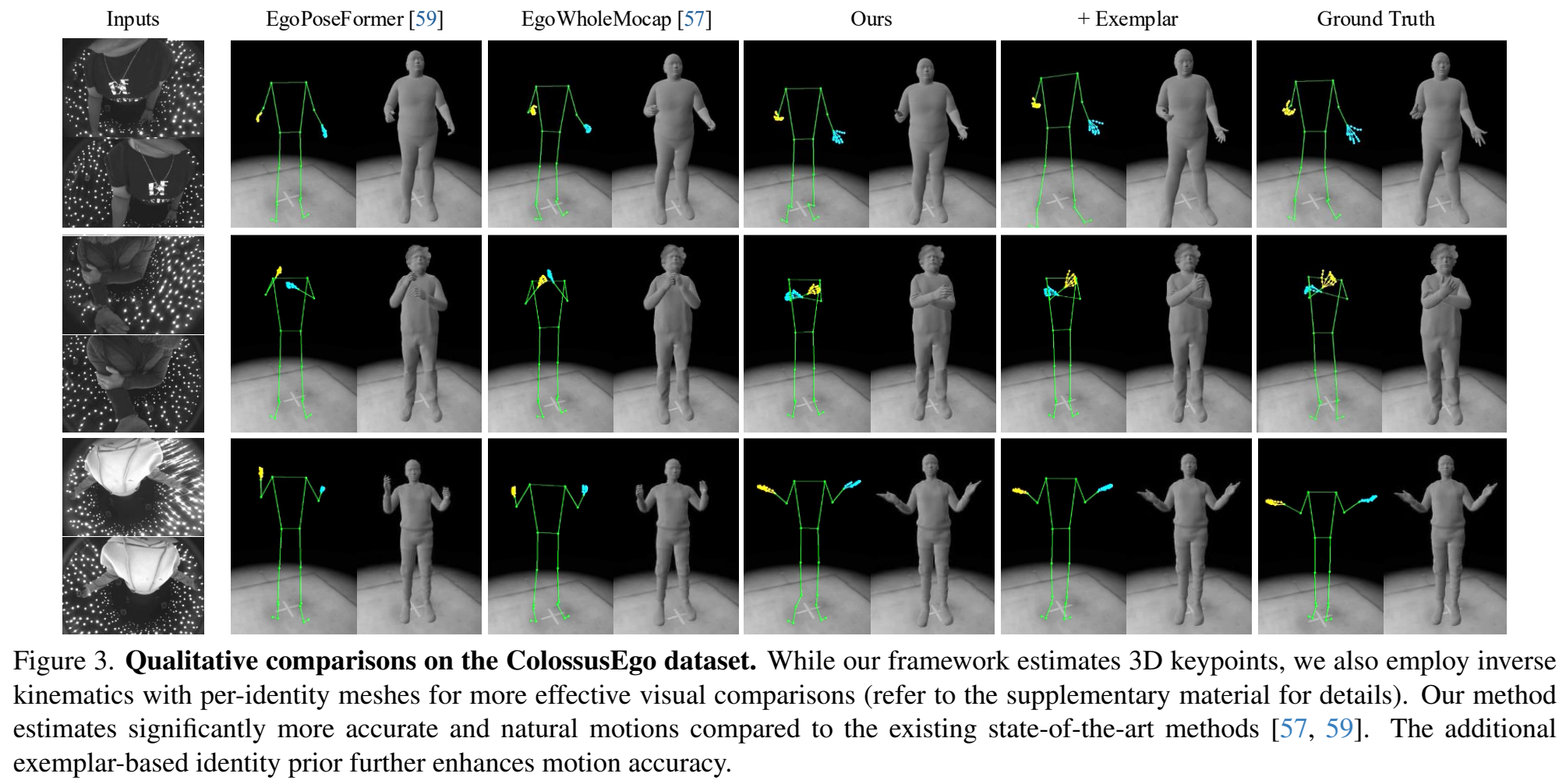
두 데이터셋에서 모든 평가 지표 기준으로 기존 방법들을 모두 능가하였으며, 아래 그림과 같이 보다 정확하고 자연스러운 모션을 생성하였다.

Identity-Aware Motion Estimation.
위의 Table 1 (a)에서, 저자들이 제안한 exemplar-based identity conditioning은 이러한 기준들 중 가장 효과적인 것을 확인할 수 있다.
Ablation Study.
저자들이 제안한 방법의 각 구성 요소가 성능에 얼마나 기여하는지에 대해 Ablation Study를 수행하였다(Table 2.)

Regression vs. Diffusion (Row A).
디노이징 디퓨전 대신 단순 regression 방식으로 모션을 추정한 결과, diffusion 기반 방식이 더 우수한 성능을 보였다.
Cascaded Body-Hand Estimation(Rows B–C).
신체와 손을 각각 별도로 추정하는 방식(Sep. Body-Hand)과 전신을 한 번에 추정하는 방식(Joint Body-Hand)을 비교하였다.
Temporal Network Architecture(Row D).
autoregressive 구조를 사용하여 임의 길이의 시퀀스를 예측하는 변형을 비교하였다. 하지만 autoregressive 모델은 teacher forcing으로 인한 exposure bias 문제를 가지며, 제안한 causal relative-temporal transformer가 더 우수한 성능을 보였다.
Diffusion Distillation(Rows E–G).
distillation 없이 1-step diffusion 모델을 직접 학습한 경우(No Diffusion Distill.) 성능이 낮았다. 반면, multi-step teacher 모델로부터 distillation한 1-step 모델은 성능과 속도 모두에서 우수하였다. 참고로 multi-step teacher 모델은 최고의 성능을 보였지만, 실시간 응용에는 속도 제한이 존재하였다.
Inference time.
distillation 적용 시 32ms, 미적용 시 274ms, 그리고 기존 SOTA는 반복과정으로 인해 2576ms가 소요되었다.


