CVPR 2025
https://arxiv.org/abs/2412.03069
Liao Qu, Huichao Zhang, Yiheng Liu, Xu Wang, Yi Jiang, Yiming Gao, Hu Ye, Daniel K. Du, Zehuan Yuan, Xinglong Wu
Introduction
Large Language Models(LLMs)의 autoregressive 프레임워크를 기반으로 NLP 분야에서 혁신을 이끌었으며, multimodal 분야에서도 강력한 성능을 보여주고 있다. 하지만 multimodal 영역에서는 perception과 generation 간에 여전히 구조적인 분리가 존재한다. 일반적으로 understanding 모델의 경우 vision encoder와 projection layer를 사용하여 pre-trained된 LLMs에 align 시키는 반면, 생성은 diffusion model이나 autoregressive 생성을 위해 discrete image token을 활용한다. 이러한 분리된 프레임워크를 통합하려는 시도도 있었지만, 주로 LLMs에 diffsuion model의 능력을 결합하는데 초점을 맞췄으며, 이는 복잡한 아키텍처와 높은 computational cost를 초래한다. 이에 대해 저자들은 보다 elegant한 통합 프레임워크의 필요성을 제기한다.
최근에는 단일 transformer 아키텍처를 사용하여 next-token prediction 방식에서 시각 정보와 텍스트 정보를 통합하려는 시도 또한 이뤄지고 있다. 구체적으로 VQ encoder를 활용하여 visual token을 discrete 하게 변환한 뒤 text token과 함께 처리함으로써, 두 입력을 모두 discrete seqence로 다룰 수 있게 된다. 이를 통해 단일 아키텍처 내에서의 end-to-end 학습이 가능해진다. 하지만 저자들은 이러한 방식이 perception과 generation의 요구를 동시에 충족시키기는 어렵다고 지적한다. 현재 대부분의 접근은 reconstruction 중심의 VQ encoder를 사용하는데, 이는 spatial 구조와 textural detail를 포착해야되는 generation에는 효과적이다. 그러나 semantic 표현을 깊이 있게 포착해야 하는 perception에는 효과적이지 않다. 한 연구에서는 별도의 인코더를 사용하여 이러한 문제를 해결하려고 시도하지만 근본적인 표현 차이를 해결하지 못한 채 모델의 복잡성만을 증가시켰다.
저자들은 이러한 문제를 해결하기 위해 understanding과 generation 간 간극을 좁일 수 있는 TokenFlow를 제안한다. 이는 dual-flow design를 통해 두 task를 모두 포괄할 수 있는 통합된 구조를 제공한다. 핵심 아이디어는 semantic과 pixel 수준의 특징 학습을 분리하면서도 shared index mapping을 통해 두 표현 간 alignment를 유지하는 것이다. 이는 semantic 유사성과 pixel 기반 유사성을 동시에 갖는 patch를 동일한 index로 mapping 함으로써, autoregressive visual generation과 동시에 multimodal understanding에 직접적으로 활용가능한 양자화된 표현을 제공한다. 저자들은 single codebook에 서로 다른 수준의 patch를 강제로 mapping 하는 것과 달리, dual codebook 구조를 통해 각 수준 별 학습을 특화함과 동시에 공유 인덱스를 통해 두 수준 간 상호 연관성을 유지할 수 있다고 주장한다.
구체적으로 TokenFlow는 dual-encoder 아키텍처를 채택하며, 각각 specialized codebook과 연결된다. semantic encoder는 CLIP 스타일 teacher로부터 학습되어 강력한 semantic prior를 제공하며 pixel encoder는 세밀한 시각 정보를 포착한다. 이후 추출된 특징들은 의미 수준과 픽셀 수준 거리의 가중 합을 최소화하는 방식으로 양자화되며, 이를 통해 joint representation space가 형성된다.
Methodology
멀티모달에서의 understanding과 generation을 하나의 next-token prediction 패러다임으로 통합하기 위해서는 입력 이미지로 부터 인덱스를 추출할 수 있는 VQ tokenizer가 요구된다. 하지만 전통적인 VQ tokenizer는 pixel 수준의 이미지 복원에서는 뛰어난 성능을 보이지만 이미지 이해 관점에서는 한계를 가진다. 이를 검증하기 위해 저자들은 다양한 tokenizer들을 LLaVA-1.5 프레임워크 내 feature extractor로 활용하여 실험을 진행하였다.
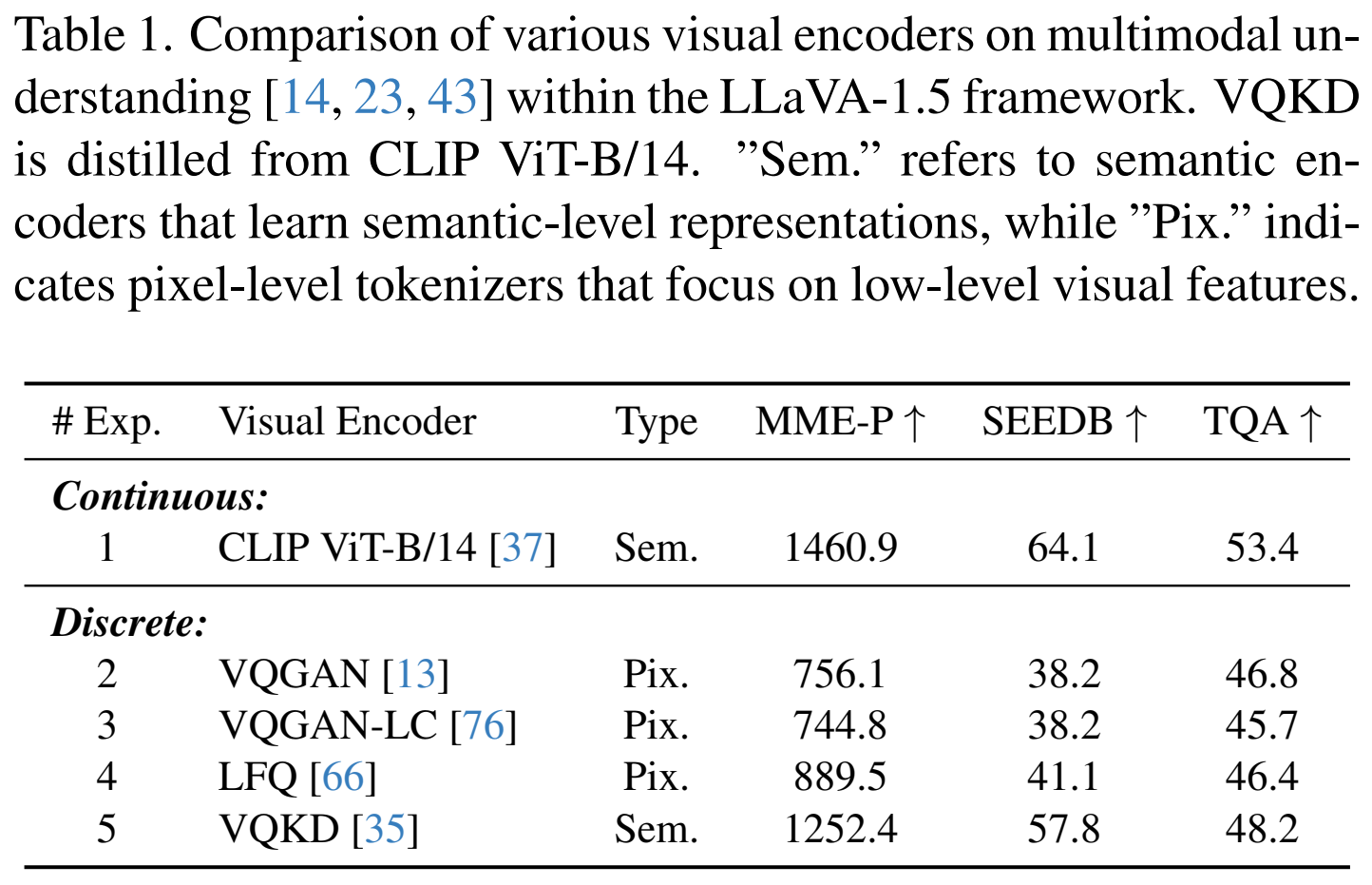
그 결과 continuous tokenize인 CLIP ViT-B 에 비해 discrete tokenizer의 성능이 일관되게 낮게 나타났다. 저자들은 이러한 성능차이가 pre-training object의 차이에서 기인한다고 본다. 기존의 VQ tokenizer는 주로 low-level reconstruction 품질을 향상시키는 데 최적화 되어있기 때문에 추출된 특징은 주로 low-level 정보에 집중되어 경향이 있다. 이로 인해 복잡한 visual reasoning 에 필요한 semantic-level의 이해가 부족하다는 것을 의미한다.
또 다른 직관적인 방식은 pre-trained된 CLIP으로 부터 discrete token을 distill한 뒤, 여기에 image reconstruction 능력을 추가하는 것이다. (이는 뒤의 experiment에서 논의한다.) 추가적으로 저자들은 VQKD가 추출한 feature로부터 원래 이미지를 reconstruction하는 실험을 수행하였는데, 아래의 그림과 같이 blurring과 high-frequency detail 손실이 발생했다.

저자들은 이러한 결과는 VQKD encoder 특성에서 기인한다고 설명한다. VQKD의 encoder는 의미적으로 유사한 patch들을 동일한 codebook index로 mapping하는 경향이 있다.

실제로 (a)와 같이 VQKD는 의미적으로 유사한 이미지들을 같은 index로 mapping하는 반면, 그림 (b)의 VQGAN은 시각적으로 유사한 이미지를 동일한 index로 mapping하며 의미보다는 low-level visual feature를 더 우선시하는 경향을 보인다. 이는 VQKD가 의미적으로는 유사하지만 시각적으로는 상이한 patch들을 같은 index로 묶을 경우, 세밀한 디테일을 복원하는 것이 매우 어렵다는 것을 시사한다. 이러한 observation은 high-level semantic understanding과 low-level visual reconstruction을 동시에 효과적으로 처리할 수 있는 새로운 tokenization 접근 방식의 필요성을 강조한다.
Unified Image Tokenizer

저자들은 이러한 gap을 해소하기 위해, semantic 수준과 pixel 수준에서 joint representation learning을 가능하게 하는 TokenFlow를 제안한다. tokenzier가 이 두 수준에서 유사한 patch를 동일한 codebook index로 mapping 할 수 있다면, 추출된 quantized feature는 autoregressive visual 생성과 multimodal understanding task에 모두 효과적으로 활용될 수 있다고 저자들은 주장한다.
Encoder.
기존 single encoder를 사용하는 기존 방식과는 달리, 본 연구에서는 semantic encoder $\varepsilon _{sem}$과 pixel encoder $\varepsilon _{pix}$로 구성된 dual-encoder architecture를 제안한다. 이러한 설계는 서로 다른 유형의 image feature를 효과적으로 추출할 수 있도록 한다. semantic encoder $\varepsilon _{sem}$는 text-aligned vision encoder로 pre-trained된 모델을 사용하는데, 이는 high-level text-aligned embedding 학습을 용이하게 한다. 이는 결과적으로 멀티모달의 이해 능력을 향상시키는 데 기여한다.
$$ \widehat{z}_{sem}=\varepsilon _{sem}(x) \in \mathbb{R}^{d_{sem}} $$
$$ \widehat{z}_{pix}=\varepsilon _{pix}(x) \in \mathbb{R}^{d_{pix}} $$
Quantization.
본 연구에서는 dual codebook을 활용하며 이는 다음과 같은 두 codebook으로 구성된다.
semantic-level embeddings : $ \textbf{Z}_{\textrm{sem}}=\{z_{sem,i}\}^{K}_{i=1}\in\mathbb{R}^{K\times d_{sem}} $
pixel-level embeddings : $ \textbf{Z}_{\textrm{pix}}=\{z_{pix,i}\}^{K}_{i=1}\in\mathbb{R}^{K\times d_{pix}} $
이때 $K$는 코드북의 entries의 수를 의미한다. 이 두 코드북은 공유된 mapping을 사용하며 이를 통해 quantization 과정에서 high-level semantic 정보와 low-level pixel details을 동시에 고려할 수 있다. 주어진 인코딩 feature $ \widehat{z}_{sem} , \widehat{z}_{pix}$ 에 대해 $l_2$-norm을 계산하여 코드북 항목들에 mapping 한다.
$$ d_{\text{sem},i} = \left\| \hat{z}_{\text{sem}} - z_{\text{sem},i} \right\|_2^2, \quad \text{for } i = 1, \ldots, K \\ $$
$$ d_{\text{pix},i} = \left\| \hat{z}_{\text{pix}} - z_{\text{pix},i} \right\|_2^2, \quad \text{for } i = 1, \ldots, K \\ $$
이후, 두 거리의 가중 합을 최소화하는 인덱스 $i^*$를 선택하여 최적의 index로 사용한다:
$$ i^* = \arg\min_i \left( d_{\text{sem},i} + w_{\text{dis}} \cdot d_{\text{pix},i} \right) $$
여기서 $ w_{\text{dis}}$는 의미 거리와 픽셀 거리 간의 균형을 조절하는 가중치이다. 또한 저자들은 코드북의 표현의 다양성을 높이기 위해 Mulit-Scale VQ(MSVQ)를 추가적으로 도입하였다.
이처럼 shared mapping 전략은 코드북이 high-level, low-level의 joint distribution을 학습하도록 하며 여러 이점을 제공한다.
⑴ Scalability: 코드북 크기가 커질수록 생성과 이해 작업 모두에서 일관된 성능 향상이 나타난다. 큰 코드북은 high-level과 low-level 특징의 다양한 조합을 가능하게 하며, 코드북 크기를 131,072까지 확장해도 95% 이상의 높은 활용률을 유지한다.
⑵ Multi-task Capabilities: semantic과 pixel-level 특징의 joint distribution를 학습함으로써, 생성과 이해 간의 gap을 효과적으로 연결할 수 있다. 또한 하나의 tokenizer가 두 작업을 모두 처리할 수 있게 되어, 구조 변경 없이 다양한 downstream task로의 확장이 가능하다.
Decoder and Training Objective.
본 연구에서는 semantic 특징과 original image를 reconstruction하기 위해 semantic decoder $\mathcal{D}_{\text{sem}}$, pixel decoder $\mathcal{D}_{\text{pix}}$ 두 개의 서로 다른 decoder를 도입한다. 또한 teacher 모델을 target feature 추출에 사용한다. 이를 통해 Semantic loss $\mathcal{L}_{sem}$ 는 teacher decoder와 semantic decoder $\mathcal{D}_{\text{sem}}$의 $\ell_2$ distance로 계산된다.
$$\mathcal{L}_{\text{pix}} = \ell_2(x, \hat{x}) + \mathcal{L}_{\text{P}}(x, \hat{x}) + \lambda_{\text{G}} \mathcal{L}_{\text{G}}(\hat{x})$$
이때 $\hat{x} = \mathcal{D}_{\text{pix}}(z)$를 의미하며, $\mathcal{L}_P(\cdot)$는 LPIPS를 사용한 perceptual loss, $\mathcal{L}_G(\cdot)$는 adversarial loss, $\lambda_G$ 는 가중치를 의미한다.
벡터 양자화 과정에서는 straight-through gradient estimator인 $z = \text{sg}[z - \hat{z}] + \hat{z}$를 적용한다.
$$\mathcal{L}_{\text{VQ}} = \left\| \text{sg}[\hat{z}] - z \right\|_2^2 + \beta \left\| \hat{z} - \text{sg}[z] \right\|_2^2$$
이를 종합하여 total training objective는 모든 loss를 합한 $\mathcal{L}_{total}= \mathcal{L}_{sem}+ \mathcal{L}_{VQ}+ \mathcal{L}_{pix}$로 정의된다.
Visual Generation with TokenFlow
Training Strategy.
저자들은 visual generation을 pre-trained LLMs을 활용하며, 이를 위해 기존의 텍스트 vocabulary에 visual tokens을 추가하여 확장된 어휘를 사용한다. 또한 기존 MLLMs와 동일하게, Tokenflow를 통해 image token을 추출하고 이를 MLP layer에 통과시킨 뒤 text token과 concatenate하여 학습에 사용한다. 차별점이 있다면 image token에만 cross-entropy loss를 적용한다.
추가적으로 classifier-free guidance를 가능하게 하기 위해 학습 중 조건 텍스트를 일정 확률로 비워두는 방식을 채택한다. 구체적으로 $p_{drop}=0.1$로 설정하여 해당 확률로 텍스트를 빈 문자열로 대체한다. 또한 학습 안정성 향상을 위해 저자들은 QK- normalization과 norm reordering 기법을 함께 적용한다.
Inference Strategy.
본 연구에서는 infernce 단계에서 새로운 multi-step sampling 방식을 제안한다. 이는 기존 top-k / top-p 샘플링 전략을 next-scale paradigm에 적용했을 때 발생하는 image collapse 및 반복적인 local patterns 문제에 대한 대안으로 제시된다. 구체적으로 초기 샘플링에서는 파라미터 $k_1$, $p_1$를 사용하여 일반적인 top-k / top-p 를 수행하고, Refinement 단계에서 1차 샘플링 결과를 기반으로 같은 스케일에서 다시 한번 샘플링을 수행하되 더 좁은 sampling 범위인 $k_2 < k_1, p_2 <p_1$을 사용한다. 이러한 점진적 샘플링 공간 축소 기법은 창의적 다양성은 유지하면서도 결과의 일관성과 품질을 강화할 수 있다고 저자들은 주장한다.
앞서 언급했듯이, 본 논문에서는 코드북의 표현력을 향상시키기 위해 MSVQ를 도입하였으며, 그 효과는 ablation study를 통해 검증하였다.

위의 표와 같이 실험 결과, Last scale만 사용하는 방식이 가장 우수하였으며, 이는 최종 스케일이 멀티모달 이해를 위해 가장 의미적으로 관련성 높은 정보를 포착하며, 추가적인 scale이나 residual feature는 오히려 노이즈를 유발하여 성능을 저하시킬 수 있음을 시사한다.
Experiments
Unified Image Tokenizer.

위 표는 TokenFlow의 256×256 및 384×384 해상도에서의 복원 성능을 나타내며 이를 통해 세밀한 시각적 디테일을 유지하는 데 있어 dual 코드북 설계의 효과를 입증하였다.
Multimodal Understanding.

multimodal understanding 실험 결과 Continuous, Discrete 방식에서 전부 SOTA 를 달성한 것을 확인할 수 있다.
Visual Generation.

저자들은 이미지 생성과 관련해 diffusion, Autoregressive 및 하이브리드 방식들과 비교를 수행하였다. 위 표에서 보여지듯, 적은 step만으로도 경쟁력 있는 성능을 보였다. 또한 inference speed 측면에서도 이미지를 한 장 생성하는데 A100 기준 단 2.7초밖에 걸리지 않아 다른 autoregressive 기반 방식보다도 우월함을 보였다.
Ablation Study


Effect of Codebook Size. 저자들은 코드북 크기에 대해 이미지 복원 품질, class-conditional 기반 생성, multimodal understanding 능력을 평가하였다. 왼쪽 그림과 같이 코드북의 크기가 커지더라도 활용률이 95% 이상으로 shared mapping 전략 덕분에 잘 유지됨을 시사하였다. FID의 경우 코드북이 커지면서 대체로 낮아짐(좋아짐)을 보였으며, VLM score 또한 동일한 추세를 보였다. 저자들은 $2^{14}$ 코드북을 선택함으로써 균형을 잡았다.
Effect of Key Design Choice. 오른쪽은 shared mapping, MSVQ, semantic encoder CLIP 초기화에 대해 ablation을 진행하였다. 표를 보면 rFID 는 CLIP Init 전까지는 성능이 오르는데 반해, 나머지는 그렇지 않다. 이는 멀티모달 이해 관점에서 semantic alignment가 중요함을 시사하며, 이미지를 생성하는데에는 그렇게 중요하지 않음을 시사한다.



