ICLR 2025
https://arxiv.org/abs/2406.05127
Shengqiong Wu, Hao Fei, Xiangtai Li, Jiayi Ji, Hanwang Zhang, Tat-Seng Chua, Shuicheng Yan
Introduction
최근 MLLMs은 입력 측에 multimodal encoder, 출력 측에 deocder를 통합한 구조를 기반으로 연구가 활발히 이뤄지고 있다. 특히 visual modality에서 이해(understanding), 생성(generating), 분할(segmenting), 편집(editing) 주요 4가지 task에 대해 SOTA를 달성하였다. 저자들은 이러한 능력의 핵심을 vision tokenization의 설계에 있다고 주장한다. 이는 입력 visual signal을 LLM이 이해할 수 있는 visual token으로 효과적으로 변환하며 주로 다음과 같은 세 가지 유형의 visual token을 생성한다:

- patch-level continuous tokens (cf. Figure 1(a))
- patch-level discrete tokens (cf. Figure 1(b))
- learnable query tokens (cf. Figure 1(c))
기존 MLLM들이 다양한 task에서 우수한 성능을 보였음에도 불구하고, 저자들은 visual tokenization 방식이 언어 토큰과 시각 토큰 간 semantic alignment에 bottleneck을 야기하고 있음을 지적한다. 언어의 경우 본질적으로 discrete 하며 이는 잘 정의된 semantic unit로 구성되어 있다. 반면, pixel로 이뤄져 있는 시각 정보는 본질적으로 continous하기에 명확한 경계를 가지지 않는다.
직관적으로 볼 때 언어 토큰은 이미지 내에서 의미적으로 완결된 객체나 구성 영역과 잘 대응되어야 한다. 하지만 Figure 1(a) 와 (b)와 같이 기존 tokenization 방식은 이미지를 fixed patch square로 나누어 객체를 patch-wise하게 분할한다. 이로 인해 semantic integrity가 훼손되고, 객체의 윤곽이나 경계선과 같은 high-frequency 정보 손실을 초례한다. 또한 Figure 1(c)와 같이 고정된 개수의 쿼리 토큰을 사용하는 방식은 실제 semantic unit과의 alignment가 어렵고 interpretability도 제한적이다.
저자들은 이러한 visual-language misalignment는 MLLM이 시각 신호를 효과적으로 처리하는 데 있어 bottle neck이 되며, 결과적으로 fine-grained semantic alignment를 요구하는 다양한 vision-language task에서 성능을 저하시키는 주요 요인으로 작용한다고 주장한다.
이에 따라 본 연구에서는 MLLM의 semantic alignment를 향상시킬 수 있는 Semantic-Equivalent Tokenizer (SeTok)을 제안한다. SeToK의 핵심 아이디어는 visual과 language token간 semantic congruent를 유도하는 데 있다. 이를 위해 입력 이미지로부터 추출된 visual feature를 클러스터링 알고리즘을 활용하여 자동으로 grouping 한다. 이때 각각의 고유한 클러스터링은 시각 내 semantic unit을 표현하게 된다.

위의 그림과 같이 SeToK에 의해 집계된 빨간색 영역은 "person" 개념에 대응되며 노랑색 영역은 "surface board" 개념에 대응된다. 또한 저자들은 이미지를 fixed-patch로 분할하는 기존 방식이 sematic 관점에서는 비효율적이라는 점을 지적한다. 서로 다른 이미지는 포함하는 semantic-unit의 수가 상이하기 때문에 구성 영역의 세분화 정도 역시 상황에 따라 유연하게 결정될 필요가 있다. 예를 들어, 어떤 경우에는 이미지 내 사람을 식별하는 것으로 충분할 수 있지만, 다른 경우에는 사람의 머리 부분을 정확히 구분해야 할 수도 있다.
이를 해결하기 위해 본 저자들은 visual tokenization의 분할 기준을 동적으로 결정할 수 있는 동적 클러스터링 메커니즘을 제안한다. 이는 density peak를 기반으로 반복적으로 클러스터 중심을 결정하고, 모든 시각적 특징이 클러스터에 할당 될 때까지 클러스터링을 수행한다. 이러한 방식은 클러스터 수를 사전에 고정하거나, 단순히 상위 k개의 시각 토큰을 병합하는 기존 방식과는 달리 semantic-unit의 토큰 수를 동적으로 결정할 수 있게 해준다.
클러스터링 이후, 저자들은 각 클러스터 내 visual feature를 집계하기 위한 token merger를 설계함으로써 high & low-frequency 정보를 모두 포함하는 완전한 visual semantic unit을 학습하도록 한다. 또한 concept-level image-text contrastive loss를 도입함으로써 언어와 시각 정보를 concept 수준에서 explicity 하게 alignment를 수행하도록 설계하였다.

pre-trained LLM을 기반으로 SETOKIM은 SeToK에 의해 생성된 visual token과 text token을 concatenation 하여 resoning을 수행한다. Inference 과정에서는 text 및 visual token을 autoregressive 방식으로 생성하며, 이후 visual detokenizer와 mask decoder를 통해 이미지와 그에 상응하는 mask로 복원한다. 또한 저자들은 unified autoregressvie training objective를 도입함으로써, 대규모 멀티모달 데이터를 대상으로 pretraining과 instruction-tuning을 통해 모델을 최적화한다.
Methodology
본 연구에서는 텍스트 토큰과 semantic적으로 align 된 시각 토큰을 생성하는 것을 목표로 한다. 이를 통해 다양한 multi-modal task에서 MLLM의 성능을 향상시킬 수 있다.
Semantic-Equivalent Vision Tokenizer

입력 이미지 $I \in \mathbb{R}^{H \times W \times 3}$가 주어졌을 때, 먼저 vision encoder를 사용하여 visual patch embedding $\mathbf{X} = {x_{i,j}} \in \mathbb{R}^{h \times w \times d}$를 추출한다. 이후 semantic적으로 완벽한 visual token을 얻기 위해, 저자들은 Token Cluster라는 방식으로 scene-level 구성 요소로 통합할 것을 제안한다.
Token Cluster.
이는 먼저 visual patch embedding $\mathbf{X}$를 입력으로 받아 각 패치를 cluster에 할당된다. 이를 수식으로 표현하면 가변적인 concept mask $M \in [0, 1]^{h \times w \times C}$을 생성하는 것으로 볼 수 있으며, 모든 패치 좌표 $(i,j)$에 대해 $\sum_c M_{i,j,c} = 1$를 만족해야 한다. 여기서 $C$는 생성되는 semantic-equivalent token의 개수를 나타낸다.
이 과정은 다음과 같은 단계로 수행된다:
- 아직 클러스터에 할당되지 않은 visual patch feature $(i,j)$ 위치를 선택함
- 선택된 위치에서의 embedding과 나머지 embedding 간의 distance kernel $\varphi(\cdot)^2$에 따라 클러스터 할당을 수행함
- 모든 embedding이 클러스터에 할당되거나, 종료 조건이 만족할 때까지 위의 두 단계를 반복함
* $\varphi(\mathbf{u}, \mathbf{v}) = \exp(-\|\mathbf{u} - \mathbf{v}\|^2 \cdot C \ln 2)$
높은 밀도를 가지는 embedding일수록 클러스터 중심이 될 가능성이 높다는 직관을 기반으로, 저자들은 visual embedding을 density peak기반으로 선택할 것을 제안한다. 구체적으로 각 토큰 $x_{i,j} \in \mathbf{X}$의 local density $\rho_{i,j}$를 이웃 정보를 바탕으로 다음과 같이 계산한다:
$$\rho_{i,j} = \exp\left(-\frac{1}{K} \sum_{x_{m,n} \in \text{KNN}(x_{i,j}, \mathbf{X})} \varphi(x_{m,n}, x_{i,j})\right)$$
이때 $\text{KNN}(x_{i,j}, \mathbf{X})$는 k-nearest neighbors를 나타낸다.
다음으로 $ x_{i,j}$보다 더 높은 밀도를 가진 다른 feature들과 minimal distance $\delta_{i,j}$를 계산한다.
$$\delta_{i,j} = \begin{cases}
\min_{m,n : \rho_{m,n} > \rho_{i,j}} \varphi(x_{m,n}, x_{i,j}), & \text{if } \exists\ m,n : \rho_{m,n} > \rho_{i,j} \\
\max_{m,n} \varphi(x_{m,n}, x_{i,j}), & \text{otherwise}
\end{cases}$$
마지막으로 각 feature의 score $s_{i,j}$는 $s_{i,j} = \rho_{i,j} \times \delta_{i,j}$로 계산된다. 이 점수를 기반으로 아직 클러스터에 할당되지 않은 feature 중 가능 높은 $s_{i,j}$ 값을 가진 위치 $(i,j)$를 선택하고, 이를 반복적으로 클러스터에 할당한다. 종료 조건이 만족되면, 남아있는 visual embeddings에 대해 추가 마스크를 부여한다.

Token Merger.
클러스터링 이후, visual embedding은 attention mask $M$을 기반으로 그룹화된다. 저자들은 각 클러스터링 내의 정보를 최적으로 유지하기 위해 visual embedding들을 aggregate하는 token merger를 채택하였다. 또한 2D position embedding을 병합함으로써 위치 정보를 추가적으로 반영하였다:
$$\hat{\mathbf{X}}_c = \text{PE}(\mathbf{X}) \odot M_c \oplus \mathbf{X} \odot M_c$$
이후 저자들은 $ \hat{\mathbf{X}}_c $에 대해 $L_\text{inner_c}$개의 Transformer layer를 적용하고, average pooling을 통해 최종 token feature를 얻는다:
$$\mathbf{u}_c = \text{Avg}(\text{Transformer}(\hat{\mathbf{X}}c, L\text{inner_c})) \in \mathbb{R}^d$$
semantic-equivalent token을 사용하여 일관된 장면 표현을 가능하게 하기 위해, 저자들은 클러스터 간 관계를 모델링하기 위한 inter-cluster Transformer layer를 추가하였다:
$$\mathbf{V} = \{\mathbf{v}_1, \cdots, \mathbf{v}_C\} = \text{Transformer}(\{\mathbf{u}_1, \cdots, \mathbf{u}_C\}, L\text{inter_c}) \in \mathbb{R}^{C \times d}$$
SeTok Training.
저자들은 MLLM 구축 시 다양한 시각적 이해 및 생성 task를 수행하기 위해 semantic-equival token이 다음 두 가지 핵심 속성을 가져야 한다고 주장한다:
- 완전하고 풍부한 고차원 의미 정보(high-level semantic information)
- 왜곡되지 않은 픽셀 수준의 세부 정보(pixel-level detail)
이에 저자들은 ①concept 수준의 image-text contrastive loss와 ②image reconstruction loss를 도입한다.
①의 경우 시각 토큰과 대응하는 텍스트 개념 간의 sematic alignment를 수행함으로써, LLM에 통합하기에 적합한 표현을 학습하도록 한다.
②는 토큰이 충분한 픽셀 수준 세부 정보를 유지할 수 있도록 도와주며, 이를 위해 토큰들을 detokenizer에 입력하여 원본 이미지를 복원하고, 이로부터 reconstruction loss를 계산한다.
최종적으로 전체 loss function은 다음과 같은 가중합으로 정의된다:
$$\mathcal{L}_{\text{setok}} = \alpha \mathcal{L}_{\text{rec}} + \beta \mathcal{L}_{\text{citc}}$$
저자들은 실험에서 $\alpha$와 $\beta$를 모두 1로 설정하였다. 또한 ImageNet-1K dataset에서는 reconstruction loss 만을 사용하고, OpenImages에서는 reconstruction + contrastive loss 모두를 사용하였다.
SETOKIM

SeTok 학습 후, 이를 pre-trained LLM과 통합하여 MLLM을 구성한 SETOKIM을 제안한다. 그림과 같이 이미지는 SeTok를 통해 semantic-equivalent visual token의 시퀀스로 토크나이저된다. 이후 텍스트 토큰과 concatenate 되어 unified multimodal sequence를 형성한다.
모달리티 간 구분과 visual generation을 위해, 두 개의 특수 토큰 $\texttt{[Img]}$와 $\texttt{[/Img]}$를 도입하여 visual 시퀀스의 시작과 끝을 명시한다. 생성된 vision token은 이후 LLM을 거쳐 visual detokenizer에 입력되어 원본 이미지를 복원한다.
저자들은 생성된 concept 중심의 토큰이 원본 이미지 내의 각 concept의 대략적인 위치 정보를 자연스럽게 내포하고 있음을 관찰하였다. 이에 따라 spatial 및 semantic encoding을 활용하기 위해 lightweight mask decoder를 추가로 도입한다. 해당 디코더는 생성된 vision token을 입력으로 사용하여 referring mask를 추출한다.
Training Objectives.
본 연구에서는 텍스트 및 시각 생성 모두에서 autoregressive modeling이 가능하기 위해 next-token prediction 방식을 채택한다:
$$p(y_1, \cdots, y_n) = \prod_{i=1}^{n} p(y_i \mid y_1, \cdots, y_i)$$
텍스트 생성의 경우, cross-entropy loss $\mathcal{L}_{\text{text}}$를 사용하여 텍스트 토큰의 likelihood를 최대화한다.
또한 이미지 생성의 경우 LLM을 사용하여 이전 토큰들로부터 조건 벡터 $z_i$를 생성한다: $z_i = \text{LLM}(y_1, \cdots, y_{i-1})$. 이후 다음 토큰의 확률은 $p(y_i \mid z_i)$로 모델링되며, LLM의 파라미터를 최적화하기 위해 diffusion loss $\mathcal{L}_{\text{vis}}$를 사용한다.

추가로 mask decoder 파라미터를 최적화하기 위해 binary cross-entropy loss $\mathcal{L}_{\text{bce}}$와 dice loss $\mathcal{L}_{\text{dice}}$를 함께 사용한다.
Training Receipts.
단일 생성 모델로 생성과 이해를 모두 수행하기 위해, 저자들은 2단계의 학습 절차를 제안한다.
Stage-1: Multimodal Pretraing. 이 단계에서는 텍스트와 이미지 간의 alignment를 강화하기 위해 초점을 맞춘다. 이를 위해 ImageNet-1L와 28M text-image pair를 통해 condition iamge generation과 image captioning task를 수행한다. 또한 LLM의 resoning capacity가 망각되지 않도록 하기 위해 SlimPajama(텍스트 전용 데이터셋)을 활용하여 영문 텍스트도 함께 학습에 사용한다. 1단계의 마지막에서는 SETOKIM의 학습 가능한 모듈들이 수렴한 시점에서 이들을 freeze하고 segmentation dataset만을 사용하여 mask decoder만 별도로 학습함으로써, fine-grained object boundary 학습을 강화한다.
Stage-2: Instruction Tuning. pre-trained weigth을 기반으로 multimodal instruction tuning을 추가로 수행한다.
* 본 실험에서는 LLM의 backbone으로 LLaMA-2-7B를 사용하였으며, vision encoder는 SigLIP-SO400M-patch14-384를 채택하였다.
Experimental results
The Quality of SeToK. 이미지 복원 및 분류 정확도 측정 결과 잘 학습된 VQ model들과 비슷한 수준의 복원 품질을 달성하는 것을 확인하였다.

Visual Understanding. 모델의 시각적 이해능력 평가 결과 다른 모델들과 달리 semantic-equivalent token을 활용한 본 모델은 경쟁력 있는 성능을 달성하였다.
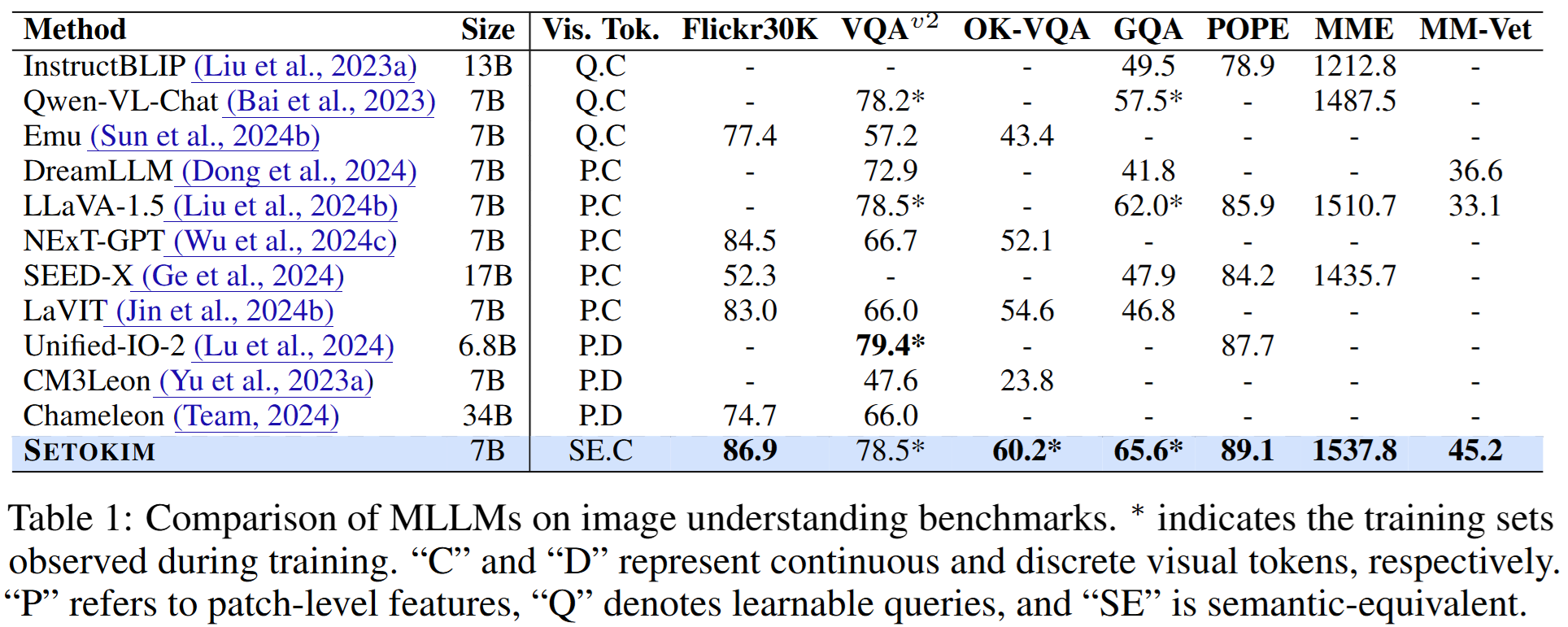
Visual Generation and Editing. 시각 생성 및 편집 성능 비교 분석 결과 기존 MLLM들에 비해 우수한 성능을 보였다.

Referring Expression Segmentation. task에 대한 MLLM 모델들의 비교 분석 결과 모든 데이터 셋에서 SOTA성능을 보임으로써, 생성된 vision token이 객체 중심의 의미 정보뿐만이라, high-frequency 경계 정보까지 효과적으로 포착함을 입증하였다.

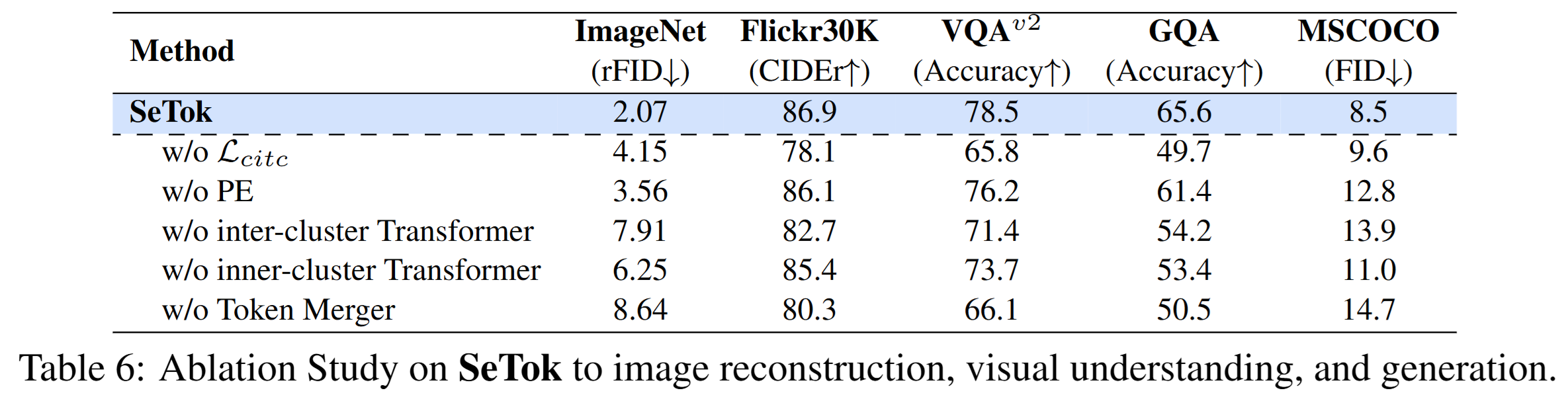
Ablation Study. 저자들은 SeTok의 설계 이점과 SETOKIM이 다양한 vision-language task에서 미치는 영향을 평가하였다.
- w/o $\mathcal{L}_{citc}$: contrastive loss를 제거하더라도 이미지 복원 품질은 유지되지만, downstream 시각 이해 과제에서는 성능이 크게 저하됨. 이는 고수준 의미 정보를 충분히 학습하지 못했기 때문으로 해석됨.
- w/o Token Merger: 클러스터 내 토큰들을 단순 평균으로 대체할 경우, 세밀한 시각 이해 및 생성 성능이 급격히 하락함. 이는 평균화 과정에서 의미 정보 손실이 발생하기 때문.
- w/o {Positional Encoding, inner-cluster, inter-cluster Transformer}: 위치 정보와 클러스터 간/내 관계 학습이 제거되면 모델 전반의 성능이 눈에 띄게 하락하여, 각 구성 요소가 정밀한 시각 표현 학습에 필수적임을 시사함.
The Impact of the Clustering Mechanism. 서로 다른 클러스터링 메커니즘이 모델 성능에 미치는 영향 비교 결과 dynamical 한 클러스터링 메커니즘을 사용한 tokenizer는 fixed 설정에 비해 전반적으로 우수한 성능을 보였으며, 동시에 학습 속도를 높이고 추론 시 computation cost 또한 줄여준다. 또한 hard-clustering이 soft-clustering에 비해 더 높은 점수를 보였는데, 이는 soft-clustering의 경우 concept이 섞여 있을 수 있어 토큰의 해석력이 떨어진다고 주장한다.

Qualitative Analysis of Visual Understanding and Generation. 뒤집힌 텍스트 "STOP"을 해독하거나 일부 가려진 “A NEW EXPERIENCE COMING YOUR WAY” 문구를 정확하게 인식하는 것을 보여준다.



Qualitative Analysis of Visual Editing. 기존 모델들과의 이미지 편집 결과, 지시 문장과의 높은 정합성과 정교한 이미지 디테일을 보존하는 것을 보였다. 또한 부분 속성 변경과 implicit한 지시를 해석하는 능력에서도 높은 성능을 보였다.

Qualitative Analysis of Visual Tokens. SeToK의 시각화 결과를 통해, 입력된 visual feature들이 semantic unit 중심으로 시각 토큰에 할당됨을 확인할 수 있다.




