Pre-print
Arxiv
Github
Google Paper
Rynaa Grover, Jayant Sravan Tamarapalli, Sahiti Yerramilli, Nilay Pande
Introduction

Multimodal Large Language Models(MLLMs)은 시각 정보와 텍스트 정보를 통합하는 능력을 바탕으로, 이미지 라벨링, 세부적인 이미지 설명, 생성 등 다양한 작업에서 두드러진 성과를 보여왔다. 이러한 성과의 핵심은 방대한 web-scale의 image-text dataset에서의 pre-training에 있으며, 이를 통해 시각적 특징과 언어 사이의 high-level semantic link을 포착하는 강력한 representation을 학습할 수 있었다.
그러나 저자들은 기존 평가 패러다임이 주로 conceptual한 능력에 치중했으며, 세밀한 perceptual acuity를 상당 부분 간과했다고 지적한다. 이로 인해 이미지 내에서 복잡한 패턴 인식이나 미세한 특징 구분과 같은 정밀한 시각 분별을 평가하는 데에는 공백이 존재한다. 따라서 본 연구에서는 단순한 semantic association만으로 해결 가능한 문제와 달리, 보다 근본적이고 인간과 유사한 시각 처리 능력을 검증할 수 있는 새로운 벤치마크 HueManity를 제안한다.
이를 위해 저자들은 인간의 색각 검사에서 전통적으로 사용되어 온 이시하라판(Ishihara plates)에서 영감을 얻었다. 이는 다양한 색상과 크기의 점들로 이루어진 배경 안에 숫자나 경로와 같은 도형을 삽입하여 색각을 평가하는 기법으로, 인간 안과학에서 널리 활용된다. 다만 저자들은 본 연구가 MLLMs의 색맹을 판별하려는 것이 아님을 강조한다. 대신, 통제된 생성 기법을 통해 제작된 이시하라 스타일 자극(stimuli)을 활용하여, MLLMs가 복잡한 점 패턴 속에서 색상과 휘도의 미묘한 대비를 기반으로 내재된 영숫자(alphanumeric) 문자를 식별할 수 있는지를 엄격히 검증한다.
저자들은 HueManity 데이터셋이 실제 복잡한 환경에서 MLLMs이 견고한 시각적 이해를 달성했는지를 평가하는 중요한 지표가 된다고 주장한다. 이시하라 스타일(Ishihara-style) 판에서 문자를 안정적으로 인식한다는 것은, 모델이 시각적 잡음에 대해 강인한 인지 능력을 지니고 있으며 동시에 패턴 인식 능력을 보유하고 있음을 의미한다. 이러한 능력은 나아가 고차원적 과제에서 미묘한 세부 사항을 정확히 해석하는 기반이 된다. 따라서 HueManity는 단순히 패턴 인식 능력을 측정하는 데 그치지 않고, MLLMs의 종합적이고 세밀한 시각 지능을 평가하며, 동시에 아키텍처적 혹은 학습적 한계까지도 드러낼 수 있는 benchmark로 기능한다.
Data Creation

HueManity 데이터셋은 총 83,850장의 이미지로 구성되며, 각 이미지는 두 글자의 영숫자 문자열, 해당 정답 레이블, 그리고 전체 생성 파라미터를 포함한다. 문자열은 소문자 알파벳(a–z), 대문자 알파벳(A–Z), 그리고 숫자(0–9)로 이루어지며, 저자들은 평가 과정에서 혼동을 줄이고 명확성을 보장하기 위해 시각적으로 모호할 수 있는 문자(예: ‘l’, ‘I’, ‘J’, ‘O’)와 ‘0’으로 시작하는 조합(예: ‘01’, 이는 ‘1’과 혼동될 수 있음)을 제외하였다. 또한 모든 유효한 두 글자 조합은 25개의 정교하게 선별된 색상 쌍으로 렌더링 되어 최종 데이터셋을 구성한다.
① Text Mask Generator.
저자들은 먼저 각 두 글자 문자열에 대해 900×900 픽셀 해상도의 binary text mask를 생성한다. 이를 위해 Pygame을 활용하여 검은색 배경 위에 흰색 글자를 렌더링 하며, DejaVu Sans font를 사용한다. 폰트는 크기 550, 굵게(bold) 및 이탤릭(italic) 스타일로 설정되었다.
② Ishihara-Style Pattern Generation.
저자들은 오픈소스 Pygame 프로젝트를 수정해 이미지를 원으로 반복적으로 채워 넣는 방식을 사용한다. 총 3만 번 이상 반복되며, 각 원은 다음 과정을 거친다:
- (x, y) 좌표를 랜덤으로 뽑고, 겹치지 않는 최대 반지름(4~15px)을 계산함.
- 원의 중심이 문자 마스크 안에 있으면 foreground, 아니면 background을 줌.
- 초기 색상에 세 가지 변환을 랜덤 적용:
- 다른 색으로의 gradient 이동
- RGB 색상 이동(−30~+30)
- 밝기 스케일링(0.66~1.5)
- 변환된 원을 해당 위치에 렌더링함
이 과정을 반복해 최종적으로 조밀한 이시하라 스타일 패턴이 만든다.
③ Color Pairs Selection.
HuManity benchmark의 25가지 색을 선정하기 위해 저자들은, 정량적 분석(CIEDE2000)과 수동 검증을 결합한 절차를 거친다:
- Initial Candidate Generation:ChatGPT를 활용하여 15개 후보 생성 후, CIEDE2000 점수와 시각적 검토를 통해 반복 정제 → 최종 25개 후보 확보
- Quantitative Contrast Filtering: CIEDE2000(ΔE2000) 분석으로 점수 25~75 사이만 유지 → 모호한 쌍(25 미만)과 지나치게 쉬운 쌍(75 초과) 제거.
- Balanced Contrast Distribution: ΔE2000 점수 50을 기준으로 절반은 <50, 절반은 >50이 되도록 배치 → 다양한 난이도 보장.
- Manual Verification: 샘플 이미지 생성 후 직접 검사 → 점수상 적절해도 실제로 배경과 비슷해 보이는 쌍은 제외.
Experiments
저자들은 9가지의 MLLMs을 평가에 활용하였으며, 이때 각각의 task별로 1,000개씩 무작위로 추출하여 실험을 진행하였다. 구체적으로 HueManity Plates(이시하라 스타일)과 Text Mask로 수행하였으며, Text Mask의 경우 기본적인 OCR 능력을 평가하기 위해 수행하였다.
Human Performance Evaluations. 저자들은 인간의 baseline을 확립하기 위해 정상적인 색각을 가지고 있는 3명의 성인 지원자로 평가하였다. 숫자 인식과 영숫자 인식 두 가지 과제에 대해 1,000개 세트에서 100개만 추출하여 평가하였다.
Traditional Computer Vision Baseline(ResNet 50). 기존 Computer vision의 baseline을 두기 위해 저자들은 ImageNet으로 pre-trained된 ResNet50을 차용하였다. 구체적으로 두 개의 classification head로 교체하였으며 각 head는 각각의 문자를 예측하도록 설계되었다. 또한 HueManity dataset에서 무작위로 2,000개로 추출한 이미지를 사용하여 fine-tuning을 진행하였다.
Results
Human Performance.

인간은 숫자 인식에 있어 완벽한 정확도를 달성하였으며, 이는 매우 간단한 작업임을 시사한다. 또한 패턴 인식에 있어서는 사실 유사한 문자 형태('s', 'c', 'w') 등을 구별하는데 어려움을 겪어 오류가 발생하였다. 저자들은 이러한 결과로 미뤄봤을 때 MLLMs은 현재 시각을 인식하는데 있어 어려움을 겪고 있음을 보여준다 주장한다.
Model Performance.
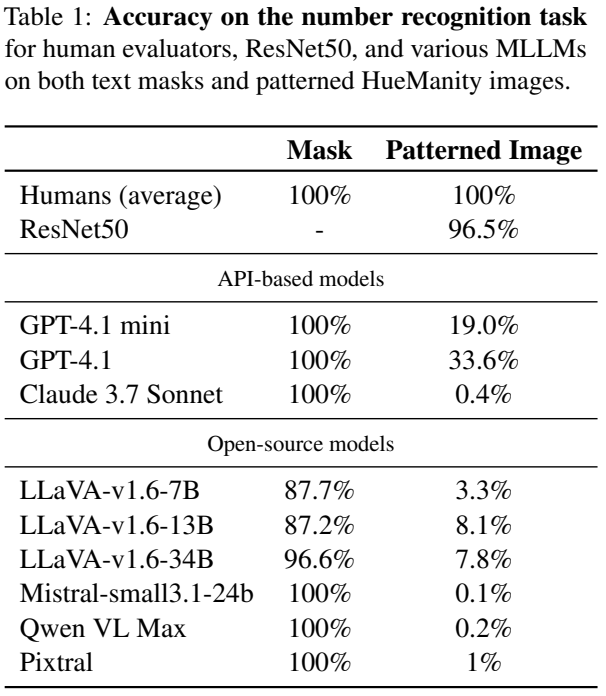

ResNet 50 Results: 기존 컴퓨터 비전 모델의 경우 인간에 근접한 정확도를 달성하였으며, 이는 근본적으로 AI에게 불가능한 과제가 아님을 보여주며 심지어 쉬운 task임을 시사한다.
MLLMs Results: 위 표는 현재 MLLMs 시각 인식에 있어 심각한 수준임을 보여준다. 이러한 결과로 미뤄봤을 때 저자들은 두 가지의 원인으로부터 비롯되었다고 주장한다.
1) visual processing pipeline: MLLMs의 vision encoder는 주로 global scene context를 포착하는데 최적화되어 있어, local detail을 포착하는데 어려움을 겪는다. 또한 visual connector는 multimodal fusion을 가능하게 하지만 동시에 information bottleneck으로 작동한다.
2) Pre-training Bias and Over-reliance on High-Level Reasoning: MLLMs 훈련 방식 자체는 미세한 지극 능력을 발달시키는 데 있어 최적화되어 있지 않다. 또한 LLM에게 과도하게 의존하다 보니 미세한 시각 단서를 기반으로 추론(Bottom-up)함으로써 미세한 시각적 단서를 놓칠 수 있다.



