ArXiv 2025
Github
Xuan Yu, Dayan Guan, Yanfeng Gu
Introduction
Multimodal Large Language Models(MLLMs)은 텍스트와 시각 정보를 결합해 다양한 분야에서 잠재력을 보여주지만, 고해상도(High-resolution, HR) 이미지를 효과적으로 처리하지 못하는 한계가 존재한다. real-world의 시각 데이터는 세부 정보가 풍부하지만, 기존 MLLMs은 고정된 vision encoder에 맞추기 위해 고해상도 이미지를 downsampling 또는 cropping 하여 처리하며, 이 과정에서 information loss가 불가피하게 발생한다.
저자들은 이러한 한계를 해결하기 위해 인간의 고해상도 시각 처리 방식에 주목한다. 인간은 장면 전체를 균일하게 받아들이는 것이 아니라, selective attention와 refinement를 통한 능동적·동적 과정을 수행한다. 연구에 따르면, 인간은 안구 운동을 통해 시선을 이동시키며, 특정 관심 영역에 중심과 시각을 집중시켜 중요한 부분을 정밀하게 분석한다.
또한 인간은 모호성이나 오류를 수정하기 위해 Self-Refinement 과정을 수행한다. 이는 가설 검증과 확인을 통해 이루어지며, 초기 해석은 추가 시각 정보를 바탕으로 반복적으로 보완된다. 이러한 메커니즘은 MLLMs 또한 장면 전체를 동시에 처리할 필요 없이, 중요 영역을 국소적으로 확대하고 정밀 분석하는 접근을 모방할 수 있음을 시사한다.
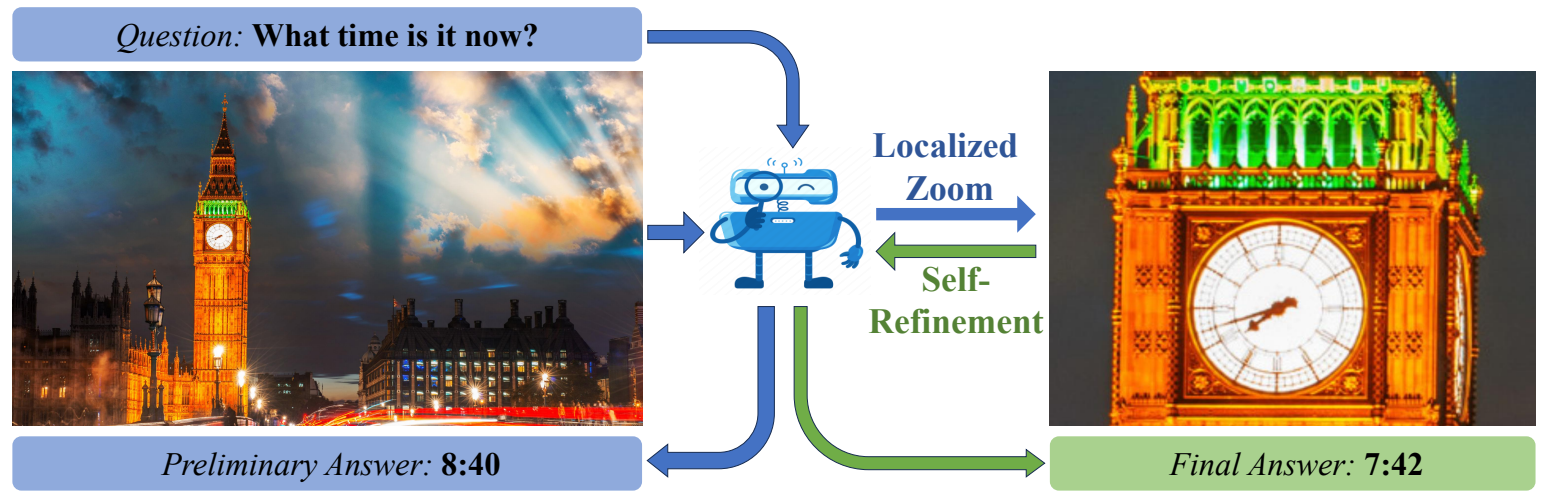
본 연구에서는 인간의 고해상도 정보 처리 방식에서 영감을 받아, Zoom-Refine이라는 training-free 프레임워크를 제안한다. 이 프레임워크는 Localized Zoom와 Self-Refinement 두 단계를 상호 보완적으로 결합하여 동작한다. 구체적으로, Localized Zoom 단계에서 MLLM은 input query를 받아 초기 답변과 함께 task와 가장 관련 있는 이미지 영역의 bounding box(bbox) 좌표를 예측한다. 이후 해당 영역을 원본 HR 이미지에서 추출한다. 이어지는 Self-Refinement 단계에서는 이 크롭 된 이미지가 다시 입력되어, 모델이 초기 답변을 refine하고 보완하여 최종 답변을 산출한다.
Method

앞서 언급한 바와 같이, Zoom-Refine은 크게 두 가지 상호 보완적인 단계로 작동한다. 먼저 Localized Zoom 단계에서는 MLLM이 관련 task에 해당하는 이미지 영역을 식별하고, 그 영역의 고해상도 뷰를 요청한다. 이어서 Self-Refinement 단계에서는 MLLM이 초기 답변을 재평가하여 최종 답변을 산출한다.
Localized Zoom Stage.
이 단계에서는 downsampled 이미지로부터 초기 답변과 관심 영역의 bbox coordinates를 추출하는 것을 목표로 한다. 구체적으로, 먼저 MLLM은 다운샘플링된 이미지와 질문을 입력받아 초기 답변을 산출한다. 이어서 위치 지정 프롬프트를 통해 관심 영역의 좌표를 예측하며, 위 그림 속 파란색 영역과 같이 관련 맥락을 충분히 포함할 수 있도록 큰 영역을 식별하도록 유도된다. 이후 추출된 bbox는 원본 고해상도 이미지에서 crop되어, 세밀한 정보를 보존한 크롭 이미지가 생성된다.
Self-Refinement Stage.
이 단계에서는 초기 질문에 대한 답변을 재검토하고, 모순을 발견하여 이를 refine 하는 것을 목표로 한다. 이를 위해 1단계의 history(질문, 다운샘플링 이미지, 초기 답변)과 함께 고해상도 크롭 이미지가 모델에 제공된다. 또한 위 그림 속 초록색 프롬프트가 함께 입력되어, 모델이 자기 수정을 수행하도록 유도한다. 이 과정을 통해 모델은 보다 정밀한 최종 답변을 산출하게 된다.
Experiments
저자들은 Zoom-Refine를 평가하기 위해 InternVL3-78B와 InternVL2.5-78B 같은 강력한 baseline에 방법을 적용하고 평가하였다. 또한 평가를 위해 task 별 프롬프트를 수정하지 않고 진행하였으며 두 가지 HR image dataset으로 평가를 진행하였다.
MME-Realworld Benchmark.

실험 결과 저자들이 제안한 방법론이 robust한 추론을 가능하게 한다는 것을 입증하였다.
HR-Bench Benchmark.

InternVL2.5-78B 환경에서 약 2~3% 점수 gain이 있는데 이게 과연 올랐다고 볼 수 있을까..?
Comparison with Training-free Methods.

위 표는 기존 TF 방식들의 reimplementation을 수행한 결과이다. 이것도 좀 의아한 게 저자들이 제안한 방법 이외에 점수가 오르지 않았으며 심지어 기존 방식들은 Forward path가 많아 inference time 또한 높다.. 믿을 수 있을까?
Analysis of Model Scales.

저자들은 모델 스케일 별 실험을 진행하였는데, 일관적으로 baseline 대비 점수가 상승한 것을 확인할 수 있다.



