Arxiv 2024
Arxiv
Github
Wenhao Wu
Introduction
ChatGPT의 등장은 LLM의 발전을 촉발했으며, 이후 GPT-4V의 도입은 MLLM(Multimodal Large Language Model)에 혁신을 가져왔다. 이를 따라잡기 위해 다양한 GPT-4V 유사 MLLM들이 제안되었고, 이들은 이미지 캡셔닝, 시각적 추론과 같은 멀티모달 과제에서 우수한 성능을 보였다.
이러한 모델들은 점차 통일된 설계와 학습 패러다임을 형성해 왔는데, 일반적으로 ① 사전 학습된 비전 인코더(vision encoder)를 통한 시각 토큰 생성, ② 대형 언어 모델(LLM), ③ 시각-언어 커넥터(vision-language connector)를 통한 시각 토큰 이해로 구성된다. 학습 과정은 두 단계로 진행되며, 첫째는 시각-텍스트 정렬(visual-text alignment)을 위한 커넥터 학습이고, 둘째는 지시문 이해 능력을 학습하는 시각 지시문 튜닝(visual instruction tuning)이다.
대부분의 MLLM은 이미지 기반으로 개발되어, 비디오 기반 MLLM의 발전은 상대적으로 더딘 상황이다. 일반적으로 이미지 기반 MLLM을 초기화한 후 비디오-텍스트 데이터셋으로 fine-tuning한다.
앞서 언급했듯이 MLLM 연구는 주로 이미지에 집중되어 있으며, 점차 강력한 모델들이 개발되고 있다. 이에 저자들은 추가적인 비디오 튜닝 없이도 고도화된 MLLM이 이미 video understanding에 필요한 지식을 보유하고 있는지 의문을 제기하였다. 이를 바탕으로, 저자들은 FreeVA라 불리는 training-free video assistant의 가능성을 탐구한다.
제안된 방법은 간단하다. 각 비디오 프레임은 이미지 MLLM의 추론 과정과 동일한 경로를 거쳐, vision encoder와vision-language connector를 통해 언어 모델이 이해할 수 있는 visual tokens을 생성한다. 여기에 parameter-free temporal aggregation을 적용하여 시간적 통합을 수행한 후, 이 토큰을 언어 모델에 직접 입력한다.
본 연구는 다음과 같은 중요한 발견을 보고한다:
- Offline image MLLM은 적절한 temporal aggregation과 결합될 때, Zero-shot 비디오 질의응답(VQA) 과제에서 SOTA(State-of-the-Art) 성능을 달성했으며, 기존의 video instruction tuning 기반 방법들을 능가했다.
- LLaVA를 VideoInstruct-100K 데이터셋으로 비디오 지시문 튜닝한 결과, 원본 LLaVA보다 성능이 오히려 저하되었다. 이는 VideoInstruct-100K 데이터셋의 효과성과 비디오 MLLM이 이미지 MLLM을 실제로 초월했는지에 대해 재평가가 필요함을 시사한다.
- Zero-shot 비디오 QA 평가지표는 GPT-3.5 API 버전 변화에 크게 영향을 받아, 시기별 비교의 공정성을 저해한다.
Methodology
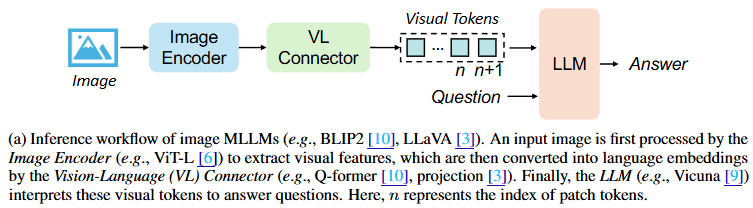
MLLM Architecture Overview.
일반적으로 MLLM은 일반적으로 세 가지 핵심 구성 요소로 구성되어 있다:
- Image encoder
- Vision-Language Connector(VL Connector)
- LLM
Inference 시 입력 이미지는 image backbone을 통해 처리되어 visual feature를 추출한다. 후에 VL connector는 이를 입력으로 받아 LLM과 alignment 되는 language embedding으로 projection 하여 LLM이 시각 토큰을 이해할 수 있게 한다. 마지막으로 이 토큰들을 활용해 텍스트 형태의 예측을 수행한다.
FreeVA: Training-Free Video Assistant.

앞서 언급한 바와 같이, 저자들은 추가적인 학습 없이 image MLLM을 비디오 모달리티로 직접 활용할 수 있는지를 탐구한다. 위의 그림과 같이 FreeVA는 매우 단순하며 직관적이다. 구체적으로, video sampler를 통해 다수의 프레임을 추출하고, parameter-free temporal aggregation 메커니즘을 도입하여 프레임 전반의 visual tokens을 통합한다. FreeVA의 핵심은 바로 이 temporal aggregation에 있다.
형식적으로 여러 프레임으로부터 얻은 visual token $X^{\text{IN}} \in \mathbb{R}^{T \times N \times D}$을 라고 할 때 이를 언어 모델에 입력하기 전 다음과 같이 집계한:
$$X^{\text{IN}} \in \mathbb{R}^{T \times N \times D} \quad \rightarrow \quad X^{\text{OUT}} \in \mathbb{R}^{K \times D}$$
여기서 $T$는 프레임 수, $N$은 프레임당 패치수, $D$는 차원, $K$는 집계된 토큰 수를 나타낸다. 저자들은 이때 두 가지 직관적인 집계 방식을 제안한다.
Sparse Aggregation.
Global Average Pooling (GAP)은 단순한 집계 방법으로 사용되는데, 저자들은 이를 Sparse Aggregation으로 분류하며 $\mathbf{S1}, \mathbf{S2}, \mathbf{S3}$ 세 가지의 방식으로 정리한다.
$\mathbf{S1}$ T-GAP. temporal dimesion에서 mean pooling을 수행
$$X^{\text{IN}} \in \mathbb{R}^{T \times N \times D} \xrightarrow{\text{T-GAP}} X^{\text{OUT}} \in \mathbb{R}^{N \times D}$$
▷ 집계된 토큰 수 $K=N$
$\mathbf{S2}$ S-GAP. spatial dimension에서 mean pooling을 수행
$$X^{\text{IN}} \in \mathbb{R}^{T \times N \times D} \xrightarrow{\text{S-GAP}} X^{\text{OUT}} \in \mathbb{R}^{T \times D}$$
▷ 집계된 토큰 수 $K=T$
$\mathbf{S3}$. T+S GAP 결합
$$X^{\text{IN}} \in \mathbb{R}^{T \times N \times D} \quad \rightarrow \quad X^{\text{OUT}} \in \mathbb{R}^{(T+N) \times D}$$
▷ 집계된 토큰 수 $K=T+N$
Dense Aggregation.
GAP을 통해 temporal 이나 spatial dimension을 직접 압축하여 sparse token을 얻는 것과 달리, 저자들은 $\mathbf{D1}, \mathbf{D2}$ 방식을 통해 더 많은 시각 토큰을 유지한다.
$\mathbf{D1}$ Full concat. 모든 프레임의 시각 토큰을 보존함
$$X^{\text{IN}} \in \mathbb{R}^{T \times N \times D} \xrightarrow{\text{Concat}} X^{\text{OUT}} \in \mathbb{R}^{(TN) \times D}$$
▷ 집계된 토큰 수 $K=T \times N$
$\mathbf{D2}$ Spatial Pool + Concat. LLM 입력 토큰 제한을 고려해, 프레임당 토큰 수를 줄이고 더 많은 프레임 정보를 포함한다. 구체적으로 $stride=\alpha$인 mean pooling으로 축소한 뒤 concat을 수행한다.
$$X^{\text{IN}} \in \mathbb{R}^{\alpha T \times N \times D} \xrightarrow{\text{Spatial Pool}} X \in \mathbb{R}^{\alpha T \times \tfrac{N}{\alpha} \times D} \xrightarrow{\text{Concat}} X^{\text{OUT}} \in \mathbb{R}^{(TN) \times D}$$
이 방식은 더 많은 프레임을 처리할 수 있다.
집계된 토큰은 LLM에 직접 입력되며, LLM은 토큰과 사용자 지시문에 따라 응답을 생성하게 된다.
Experiments
Implementation Details.
모든 실험은 단일 40G A100 GPU에서 수행 가능하다. 본 연구에서는 이미지 기반으로 학습된 MLLM, 즉 LLaVA-1.5, InstructBLIP, InternVL, Dense Connector를 사용하여 비디오 도메인으로 확장하였다. 전체 비디오에서 균일하게 샘플링된 $T$개의 프레임을 입력으로 사용하며, 이는 LLM의 토큰 제한이 허용하는 범위 내에서 조정될 수 있다.
Dataset.
본 방법은 추가 학습을 요구하지 않으며, zero-shot 성능을 open-ended video QA 벤치마크(MSVD-QA, ActivityNet-QA, MSRVTT-QA, VideoChatGPT)에서 평가한다. 해당 벤치마크는 정보의 정확성(Correctness of Information, CI), 세부 지향성(Detail Orientation, DO), 맥락적 이해(Contextual Understanding, CU), 시간적 이해(Temporal Understanding, TU), 일관성(Consistency, CO) 등의 지표를 포함한다. 모든 평가에는 GPT-3.5 assistant가 사용되었다.
Sparse vs Dense Temoral Aggregation.

Sparse Temporal Aggregation. Table 1(a)에서 확인할 수 있듯, 비디오 프레임 수를 증가시키는 것이 반드시 성능 향상으로 이어지지 않는다. 구체적으로, 100 프레임을 사용하는 경우는 단 1 프레임만 사용하는 경우보다 더 나은 결과를 보여주지 못하였다. 이는 오프라인 이미지 MLLM의 비전 인코더가 생성한 시각 토큰이 이미 LLM에 의해 충분히 이해될 수 있는 상태임을 의미한다. 그러나 시간 차원에서 프레임을 mean pooling을 하면 각 프레임의 패치 토큰 특징이 손상되며, 프레임 수가 많아질수록 이러한 손상이 누적되어 LLM의 시각 토큰 이해 능력이 약화된다.
Dense Temporal Aggregation. Table 1(b)에 나타난 결과와 같이, 프레임 수를 늘리면 성능이 뚜렷하게 향상되었으며, Sparse Aggregation보다 훨씬 높은 성능을 달성하였다. 그러나 프레임 수를 8로 늘리면 LLM의 토큰 제한을 초과하여 성능이 급격히 저하되는 것이 관찰되었다. 이는 LLM의 토큰 제한 내에서 시각 토큰 수를 최대화하는 것이 성능 향상에 효과적인 방법임을 시사한다.
Aggregation Methods.

Aggregation 방법에 대해 저자들은 광범위한 분석을 실시하였다. 먼저 projection 이후 시각 토큰을 집계하는 것이 더 나은 성능으로 이어진다는 것을 발견하였다. 이는 이미 projection 이후 LLM과 잘 alignment가 되어 있음을 시사한다.
sparse aggregation과 관련해서, temporal mean pooling 외에도 spatial dimension에서의 풀링을 시도했지만, 결과는 현저히 저조하였다. 이는 각 프레임의 원래 패치 토큰을 유지하는 것이 중요함을 시사하며, 결론적으로 S3(S1 + S2) 또한 좋은 결과를 보이지 못하였다.
dense aggregation에서의 효과는 확실히 입증되었다. LLM의 입력 토큰 제한을 고려하여, 더 많은 프레임 정보를 포함하기 위해 프레임당 패치 토큰 수를 압축하는 방법을 고려하였다. 저자들은 stride=2인 max pooling을 사용하여 각 프레임의 패치 토큰 수를 줄이되, 풀링 된 토큰이 원래 토큰에서 비롯되도록 하였다. 이 접근 방식은 추가적인 성능 향상으로 이어졌다.
Existing Video Instruction Tuning.

저자들은 video instruction tuning의 효과를 검증하였다. 이를 위해 VideoChatGPT의 방식을 따라, 다중 프레임에서 토큰을 집계하기 위해 temporal mean pooling을 적용하고, VideoInstruct100K를 활용하여 LLaVA-1.5를 학습시켰다. 그러나 Table 3의 결과에서 보이듯, projection을 학습한 후의 성능은 오히려 원본 LLaVA-1.5를 직접 사용하는 것보다 저하되었다. 더욱이 projection과 LLM을 동시에 업데이트할 경우 성능은 한층 더 크게 감소하였다.
또한 저자들은 VideoChatGPT 논문이 학습 이후 결과만을 보고하고, 초기화된 파라미터와의 비교를 제공하지 않았음을 지적하며 추가 실험을 수행하였다. 그 결과, Table 4에서 확인되듯 VideoChatGPT가 제공한 학습된 파라미터를 사용하는 것이, 초기화된 파라미터(즉, 학습되지 않은 상태)를 직접 사용하는 것보다도 성능이 낮았다. 이는 VideoChatGPT가 원래의 LLaVA가 가진 능력을 초과하는 학습을 이루지 못했을 가능성을 시사한다.
Scaling Results on LLM.

LLM 확장 실험 결과 FreeVA는 두 개의 데이터 셋에서 모두 추가적인 성능 향상을 달성한다. 또한 D2 방식이 일관되게 D1 방식보다 약간의 성능 개선을 보이는 것도 확인할 수 있다.
Impact of GPT-3.5 Versions on Evaluation Result.

위 결과가 보여주 듯 GPT-3.5 버전에 따라 전혀 다른 결과를 산출할 수 있다. 예를 들어, GPT-3.5-Turbo-0301 버전을 사용해 평가한 성능은 다른 버전들보다 현저히 높았다.
Zero-shot Video QA.

GPT-3.5 버전에 따라 점수가 달라질 수 있다는 관찰을 토대로, 저자들은 다양한 버전으로 평가한 결과를 함께 제시한다. 특히 MAR 버전에서는 FreeVA(LLaVA-1.5 기반)가 세 가지 데이터셋 모두에서 VideoChatGPT, Valley 같은 초기 연구들을 압도적으로 뛰어넘는 성능을 보여주었다.
JUN 버전을 사용했을 때도 결과가 흥미롭다. 비디오 데이터를 대규모로 학습시킨 Video-LLaVA나 LLaMA-VID 조차 FreeVA보다 성능이 낮았다. Video-LLaVA는 Valley에서 추출한 70.2만 video-text pairs로 사전학습하고 VideoInstruct100K로 튜닝까지 했고, LLaMA-VID는 WebVid 2.5M에서 추출한 23.2만 video-caption pairs로 학습하고 역시 VideoInstruct100K로 튜닝을 했다. 하지만 FreeVA 이런 video transfer training을 전혀 거치지 않았음에도, 특히 ActivityNet-QA에서 압도적으로 좋은 성능을 보여준다.
MovieChat은 short-term and long-term memory mechanism 설계를 통해 긴 비디오 이해를 지원한다. 그러나 단순한 FreeVA가 MSRVTT-QA와 ActivityNet-QA 모두에서 MovieChat보다 훨씬 더 우수한 성능을 보였다.
Video-Based Text Generation Performance.

Training-Free에도 불구하고 비교적 안정적인 text generation 성능을 보여주었다.



