CVPR 2025
Arxiv
Github
Jaeseong Lee, Yeeun Choi, Heechan Choi, Hanjung Kim, Seonjoo Kim
Introduction

Multimodal Large Language Models(MLLMs)은 이해(understanding), 추론(reasoning), 생성(generation) 능력에서 강력한 성능을 보여주며, 이를 기반으로 한 다양한 제품들이 산업을 변화시키고 인간의 효율성을 향상시키고 있다. 그러나 MLLMs은 고해상도 이미지에서 정확한 위치 파악과 추론(reasoning)을 요구하는 과제에서 한계를 보인다.
이는 사전 학습된 이미지 인코더와의 일관성을 유지하기 위해 MLLMs이 고정된 이미지 해상도에서 fine-tuning되었기 때문이다. 이로 인해 고해상도 이미지를 직접 입력하면 일반화 성능이 저하되며, 반대로 다운샘플링을 적용하면 일관성은 유지되지만 세밀한 시각적 정보가 손실되어 디테일을 포착하는 능력이 저하된다.
이러한 문제를 해결하기 위해 이전 연구에서는 크게 두 가지 방향으로 탐구해왔다. 첫 번째는 고해상도 데이터셋으로 학습된 특수 모듈을 추가하는 방법이다. 하지만 이 방식은 데이터셋 구축 및 수작업 설계가 필요하고, 방대한 computation resources을 요구하기 때문에 비효율적이다.
두 번째는 training-free task-specific two-stage 프레임워크를 사용하는 것이다. 구체적으로 고해상도 이미지를 패치로 분할한 뒤, 각 패치에 대한 예측을 score averaging이나 tree-like structure로 결합하는 방식이다. 이 접근법은 추가적인 학습이 필요 없다는 장점이 있지만, 특정 과제에 맞춘 heuristic design에 의존하기 때문에 일반화에는 한계가 존재한다.
이에 따라 저자들은 과제 특화 설계 없이도 적용 가능한, 즉 training-free task-agnostic 프레임워크를 설계하고자 한다. 이는 실험적 관찰에 기반한 것으로 MLLM이 고해상도 이미지에서는 어려움을 겪더라도, 다운샘플링 된 이미지에 대한 예측은 여전히 어디에 주목해야 하는지에 대한 implicit understanding를 가지고 있다고 가정한다. 이는 성능 저하가 발생하더라도, MLLM이 세밀한 정보가 손실된 상황에서도 여전히 coarse localization ability을 유지한다는 점을 시사한다.
이러한 insight를 활용하여 저자들은 Extract Candidate then Predict(ECP) 라는 training-free한 task-agmostic 두 단계 프레임워크를 제안한다. 이는 고해상도 이미지에서의 MLLM 성능을 향상시키기 위해 설계되었다.
첫 번째 단계에서 Extract Candidate (EC)는 고해상도 이미지의 다운샘플링 버전을 MLLM에 입력하여 instruction 관련 후보 영역을 추출한다. 후에 Predict (P) 단계에서는 추출된 후보 영역에 기반하여 최종 예측을 수행한다. 즉 고해상도 이미지 이해를 coarse → fine 과정으로 분해함으로써 기존 문제를 완화하면서도 세밀한 시각 정보를 보존한다.
Methodology

Stage 1: Extract Candidate (EC).
저자들은 MLLM이 고해상도 이미지에 대해 위치 파악 및 추론에 있어 어려움을 겪지만, 여전히 이미지에서 어느 영역에 집중해야 하는지는 식별할 수 있다고 가정한다. 이 단계에서는 고해상도 이미지에 대한 지시문에 대해 즉시 답변을 생성하지 않는다. 대신 지시문과 관련된 영역을 찾아내며, 이 영역 이후 지시문에 대해 집중해야 될 부분이 되며 바운딩 박스로 표현된다.
이를 위해 본 논문에서는 사전 학습된 MLLM $\mathcal{F}_{EC}$을 사용한다. $\mathcal{F}_{EC}$는 고해상도 이미지와 instruction을 입력으로 받아 관심 지점(point)이나 바운딩 박스를 생성한다:
$$O_{point} = (x, y), \quad O_{bbox} = (x_{1}, y_{1}, x_{2}, y_{2}) $$
이후 출력에 따라 대표 좌표를 정의하는데, point의 경우 좌표를 그대로 사용하며 바운딩 박스의 경우 중심을 계산한다.
후에 이 중심 좌표를 중심으로 저자들은 고정된 크기의 바운딩 박스를 새로 정의한다. 구체적으로 바운딩 박스는 대표 좌표를 중심으로 하이퍼파라미터 $w, h$를 각각 너비와 높이로 사용하여 정의된다. 이때 $w<W,h<H$이며 실험에서는 $w=1024, h=1024$로 설정하였다.
또한 만들어진 바운딩 박스가 이미지 경계에 벗어나지 않도록 다음과 같이 보정한다:
$$x_{left} = \max(0, \min(x_{rep} - w/2, W - w))$$
$$y_{top} = \max(0, \min(y_{rep} - h/2, H - h))$$
$$x_{right} = x_{left} + w,\quad y_{bottom} = y_{top} + h $$
Stage 2: Predict (P).
이 단계에서는 이전 단계에서 식별된 바운딩 박스를 기반으로 최종 예측을 수행한다. 구체적으로, 바운딩 박스로 crop된 이미지 패치를 입력으로 활용하여, MLLM이 세밀한 시각적 정보를 포착할 수 있도록 한다. 또한 task가 global context까지 요구하는 경우 crop된 이미지와 더불어 다운샘플링된 전체 고해상도 이미지 또한 입력으로 사용한다.
Experiments
본 논문에서는 기존의 single-stage와 two-stage 프레임워크(ECP)를 4K GUI grounding과 4K 및 8K MLLM perception 두 가지 task에서 비교하였다.
GUI Grounding.

실험 결과, single-stage에서는 모든 MLLM이 고해상도 GUI 이미지에서 극히 낮은 성능을 보였다. 하지만 저자들이 제안한 ECP의 경우 일관된 성능 향상을 보이며 고해상도 이미지 문제를 효과적으로 해결함을 보여준다.
Ablation Study. EC 단계에서 저자들은 instruction-guided region selection 대신 random sampling을 적용해 ablation study를 수행하였다. 그 결과 고해상도 이미지에서는 어려움을 겪지만, 의미 있는 영역을 효과적으로 식별할 수 있다는 저자들의 가정을 검증하였다.
MLLM Perception.
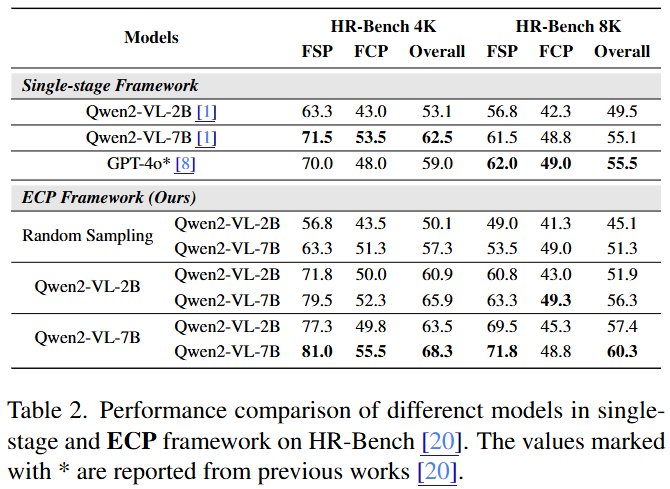
실헝 결과, ECP가 MLLM의 작은 단일 객체를 정확히 해석하는 능력을 크게 향상시켰음을 보여주었다.


Qulitative 결과 ECP는 대략적인 위치 파악 후 crop된 이미지를 통해 정확한 답변을 생성하는 것을 보여준다.



